
In this blog post you will learn everything you need to start deploying your projects in DBT Cloud. I will explain what environments, jobs, and runs are and their relationship, as well as two architectures for merging your code into development. Lets begin.
Environments:
Environments define the context of your work in DBT. Specifically, they determine how DBT Cloud will execute your project. There are three essential aspects to a DBT environment:
- The version of DBT you are going to work with.
- The git branch that will store your code alterations.
- The data location you are working on, which involves both the data location DBT will read to execute your code, and the target where you would like DBT to materialize your models.
Environments are generally useful to fine-tune settings in accordance to the various needs you’ll have at different stages of your project. There are two types of environments in DBT cloud:
1) Development:
The development environment determines the settings used while working in DBT Cloud. There is only one development environment for a single DBT cloud project. This is important to ensure that all developers working within the same project are using the same version of DBT. While this ensures consistency, git allows them to collaborate effectively, by working on different branches and resolving any conflicts in their code. Finally, each developer can set up their own schema on the target data location to ensure that there are no conflicts between materializations.
2) Deployment:
The deployment environment determines the settings a job will use when executed. You can have as many deployment environments as you may want or need. For deployment environments, you can set up all three aspects of a DBT environment in its definition.
The following table illustrates this:
| Purpose: | Developer 1 | Developer 2 | Developer 3 | Deployment |
| DBT version: | 1.7 | 1.7 | 1.7 | 1.7 |
| Git Branch: | core/orders | staging/sources | tests/generic | main |
| Schema: | dbt_dev1 | dbt_dev2 | dbt_dev3 | Analytics |
Jobs:
A job is a sequence of DBT commands that you can run on a schedule or trigger through some other means. You can set up a job to run any commands, such as run or test, but the recommended option for deployment is to execute dbt build, which will run your models, execute tests and create snapshots and seeds, in DAG order. This will ensure maximum deployment quality.
One common setup is to have two jobs: One every sunday night executing a build –full-refresh command which will and one every weekday morning executing a build command.
It is also important to note that each time a job runs, the results of the execution of each command are stored in the ‘run results’. These contain valuable information about your model, such as the average model runtime, test failure rates, number of record changes captured by snapshots and other interesting facts. You can also enable notifications, which will inform you through email or slack of whether a certain job has passed, failed or been cancelled.
Deployment Architecture:
Deployment architecture refers to the way you organise the automatic execution of your jobs into different locations in your data platform. Architecture matters because it allows us to run and test our dbt projects in various stages of development. It is important to have a clear strategy for updating your code and adding features to a deployed product, especially if it is currently in use. This is what a good deployment architecture does for you.
There are two main promotion strategies:
1) Direct or ‘one trunk’ promotion:
On this strategy, feature branches are merged directly into the main, production branch. Hence, testing only takes place in their allocated branches before merging. This makes the strategy a form of continuous deployment: features deploy continuously as the developers finish working on them.
While this strategy will quicken the implementation of features, it runs the risk of merging bad code into the main branch, or of running into unforeseen problems due to incompatibilities between features.
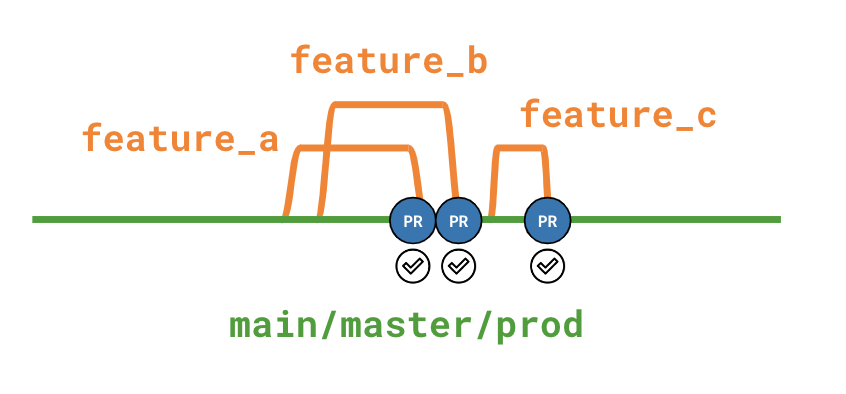
2) Indirect or multiple trunks promotion:
On this strategy, multiple feature branches are first merged into an intermediate branch, which is used for thorough testing, before merging the intermediate branch into the main, production branch. The intermediate branch can be helpful to fully test how the different features interact with one another before merging into the main branch for deployment. This is a safer, albeit more sluggish, strategy.

References:
https://docs.getdbt.com/guides/set-up-ci?step=1
https://docs.getdbt.com/docs/dbt-cloud-environments



