During my formation on Snowflake at Nimbus Intelligence our professor showed us a query that appeared to be nesting Group By and Partitioning in order to calculate a percentage. Morever, the query was using a total of three aggregate functions in the same line. In this post, we will analyze and understand how SQL handles these queries that may seem daunting at first sight.
Let’s first introduce some context. We will work on the Snowflake Sample Data TPC-H using schema TPCH_SF1. More specifically, we will be focusing on the following orders table.
| orders(o_) | type |
|---|---|
| orderkey | INT |
| custkey | INT |
| orderstatus | VARCHAR |
| totalprice | DECIMAL |
| orderdate | DATE |
| orderpriority | VARCHAR |
| clerk | VARCHAR |
| shippriority | VARCHAR |
| comment | VARCHAR |
Here is an example of the attributes that we will be looking at
USE SCHEMA snowflake_sample_data.tpch_sf1;
SELECT o_orderkey, o_clerk, o_orderpriority FROM orders LIMIT 6;
| o_orderkey | o_clerk | o_orderpriority |
|---|---|---|
| 1,800,001 | Clerk#000000306 | 1-URGENT |
| 1,800,002 | Clerk#000000897 | 3-MEDIUM |
| 1,800,003 | Clerk#000000137 | 4-NOT SPECIFIED |
| 1,800,004 | Clerk#000000481 | 2-HIGH |
| 1,800,005 | Clerk#000000471 | 3-MEDIUM |
| 1,800,006 | Clerk#000000648 | 4-NOT SPECIFIED |
Our aim is to find the percentage of each of the different order priorities ordered by each clerk. In essence, a table that looks like this
| Clerk (Simplified) | Order_Priority (Simplified) | Percent |
|---|---|---|
| Clerk_1 | Urgent | 25 |
| Clerk_1 | Normal | 40 |
| Clerk_1 | Low | 35 |
| Clerk_2 | Urgent | 10 |
| Clerk_2 | Normal | 70 |
| Clerk_2 | Low | 20 |
| … | … | … |
Prerequisites
- Aggregation in SQL both with
GROUP BYandPARTITION BY - Common Table Expressions
Standard/Legible approach
A standard approach would probably be to first obtain the total amount of orders of each clerk, so we need to group by clerk, save this in a CTE, and then find the amount of orders for each clerk and priority, so we need to group by clerk and order priority. Notice that we require two GROUP BY that use different attributes. This forces us (not really, as we will see in the next section) to use more than a single query to obtain the results.
The first query looks like this
SELECT DISTINCT
o_clerk,
COUNT(*) AS total_orders
FROM orders
GROUP BY o_clerk
ORDER BY o_clerk; -- for legibility
and provides the following results
| clerk | total_orders |
|---|---|
| Clerk#000000001 | 1,467 |
| Clerk#000000002 | 1,494 |
| Clerk#000000003 | 1,538 |
| Clerk#000000004 | 1,502 |
| Clerk#000000005 | 1,503 |
| … | … |
Then, we store this table on a CTE and use it in a subsequent query where we GROUP BY o_clerk and o_orderpriority to count the amount of orders of each priority of each clerk
WITH clerk_orders AS (
-- our previous query
SELECT DISTINCT
o_clerk,
COUNT(*) AS total_orders
FROM orders
GROUP BY o_clerk
)
-- the new query to find the percentage of orders for each clerk and order priority
SELECT
orders.o_clerk,
orders.o_orderpriority,
100 * COUNT(*) / clerk_orders.total_orders AS pctg_of_orders
FROM orders
INNER JOIN clerk_orders
ON orders.o_clerk = clerk_orders.o_clerk
GROUP BY orders.o_clerk, orders.o_orderpriority, clerk_orders.total_orders
ORDER BY orders.o_clerk, orders.o_orderpriority; -- for legibility
Note that, besides grouping by orders.o_clerk and orders.o_orderpriority, we must add clerk_orders.total_orders so that SQL understands what to do with this column. The result, as expected, is the following
| o_clerk | o_orderpriority | pctg_of_orders |
|---|---|---|
| Clerk#000000001 | 1-URGENT | 19.90 |
| Clerk#000000001 | 2-HIGH | 19.90 |
| Clerk#000000001 | 3-MEDIUM | 19.70 |
| Clerk#000000001 | 4-NOT SPECIFIED | 20.52 |
| Clerk#000000001 | 5-LOW | 19.97 |
| Clerk#000000002 | 1-URGENT | 19.75 |
| Clerk#000000002 | 2-HIGH | 19.54 |
| Clerk#000000002 | 3-MEDIUM | 20.21 |
| … | … | … |
Nesting Group By and Partitioning
The solution provided by our teacher was the following
SELECT
o_clerk,
o_orderpriority,
100 * COUNT(*) / SUM(COUNT(*)) OVER (PARTITION BY o_clerk) AS pctg_of_orders
FROM orders
GROUP BY o_clerk, o_orderpriority;
As you can see, it is quite more compact than our previous solution. Note, however, that it is very hard to understand what is happening at first sight. There are three aggregate functions, two COUNT and a SUM, which are grouped using a PARTITION BY o_clerk and a GROUP BY o_clerk, o_orderpriority.
How does SQL know which functions to use for which groupings? In the nested SUM(COUNT(*)), is the COUNT referring to the PARTITION BY and the SUM to the GROUP BY, or the other way around? Which grouping function is taking care of the COUNT in the numerator?
Let’s dissect it and perform a couple of tests to find out!
Making sense of Nesting Group By and Partitioning
First of all, let’s see what partitioning over o_clerk produces
SELECT DISTINCT
o_clerk,
o_orderpriority,
COUNT(*) OVER (PARTITION BY o_clerk) AS orders_by_clerk
FROM orders
ORDER BY o_clerk, o_orderpriority; -- for legibility
| o_clerk | o_orderpriority | orders_by_clerk |
|---|---|---|
| Clerk#000000001 | 1-URGENT | 1,467 |
| Clerk#000000001 | 2-HIGH | 1,467 |
| Clerk#000000001 | 3-MEDIUM | 1,467 |
| Clerk#000000001 | 4-NOT SPECIFIED | 1,467 |
| Clerk#000000001 | 5-LOW | 1,467 |
| Clerk#000000002 | 1-URGENT | 1,494 |
| Clerk#000000002 | 2-HIGH | 1,494 |
| … | … | … |
As expected, for every clerk it provides the total amount of orders. Therefore, we can already discard that the partition is taking care of either of the two COUNTs in the original query. In said COUNTs, we need the grouping by o_clerk and o_orderpriority in order to provide the correct results.
Just to confirm, grouping by o_clerk and o_orderpriority
SELECT
o_clerk,
o_orderpriority,
COUNT(*) AS orders_by_clerk_and_priority
FROM orders
GROUP BY o_clerk, o_orderpriority
ORDER BY o_clerk, o_orderpriority;
provides
| o_clerk | o_orderpriority | orders_by_clerk_and_priority |
|---|---|---|
| Clerk#000000001 | 1-URGENT | 292 |
| Clerk#000000001 | 2-HIGH | 292 |
| Clerk#000000001 | 3-MEDIUM | 289 |
| Clerk#000000001 | 4-NOT SPECIFIED | 301 |
| Clerk#000000001 | 5-LOW | 293 |
| Clerk#000000002 | 1-URGENT | 295 |
| Clerk#000000002 | 2-HIGH | 292 |
| Clerk#000000002 | 3-MEDIUM | 302 |
| … | … | … |
Therefore, we can infer that the COUNTs are being taken care by the GROUP BY and the SUM by the partitioning.
At first it may seem weird and arbitrary, but it actually makes kind of sense. First, we must remember the order of operations of SQL (see table below). Knowing that window functions and partitions are taken care in the SELECT statement, we can see that GROUP BY occurs first, and, therefore, it must take care of the «first level» of aggregate functions.
| Order | Clause |
|---|---|
| 1 | FROM |
| 2 | WHERE |
| 3 | GROUP BY |
| 4 | HAVING |
| 5 | SELECT |
| 6 | ORDER BY |
| 7 | LIMIT |
In the numerator, there is only a COUNT, so it calculates it by the specified grouping (o_clerk and o_orderpriority). In the denominator there are two nested functions, SUM(COUNT(*)). Evidently, the COUNT must be calculated before performing the SUM (meaning that COUNT is the «first level» function here) and, indeed, the GROUP BY takes care of it.
Then, once we reach the SELECT statement, the PARTITION BY receives a column that can be thought of something similar to
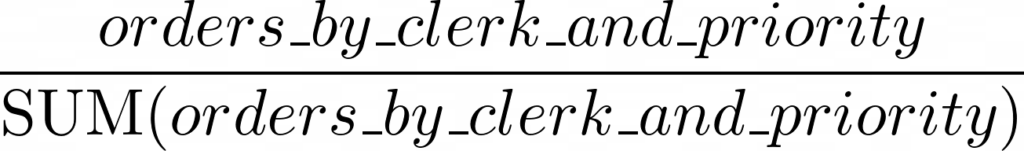
where orders_by_clerk_and_priority are the values previously calculated by the GROUP BY. Therefore, the PARTION BY simply sees a SUM that must be calculated for every clerk, providing in the denominator the total amount of orders of each clerk.
Summary
In this blog, we have made sense of the nesting Group By and Partitioning query that initially seemed complicated and intimidating by approaching the problem with a «divide and conquer» mindset. As a result, we have added to our toolset a new method for performing queries that require several GROUP BYs with different aggregating keys. This method of nesting Group By and Partitioning lets us write much more compact queries that avoid using CTEs.



