This short Git tutorial will explain the main ideas of this amazing software that helps anyone who works with code or files that undergo frequent changes, and are being worked on by multiple people.
What is Git?
Git is a [piece of] software that belongs to the category of Version Control Systems (VCS). A VCS allows you to manage and collaborate on different versions of your code. It was created by Linus Torvalds, the creator of Linux, in 2005. Git works by tracking changes in files and storing them in a repository, which is simply a directory that contains the history of your project. You can create branches to work on different features or bug fixes, and merge them back into the main branch when they are ready.
Version Control Systems Categories
Local VCS
A Local VCS works by keeping patch sets (that is, differences between files) in a special format on your disk; it can then re-create what any file looked like at any point in time by adding up all the patches. If you are working solo, these local systems are excellent, but they do not support teamwork, since all patches are stored locally on your machine.
Developers created centralized and distributed VCSs to solve this problem.
Centralized VCS
Just like a Local VCS, a Centralized VCS stores files and changes, but on a remote server.
You can pull the latest version from the server to download a local copy on your machine, and push your changes to the server when they are ready. A centralized VCS is easy to use and offers full visibility of the project state, but it also requires constant connection to the server and may cause conflicts when multiple developers work on the same files.
Distributed VCS
A Distributed VCS (DVCS) utilizes a peer-to-peer approach. Unlike a centralized version control system, where there is only one server that contains all the versions of your project, a DVCS allows each user to have a local copy of the entire repository, including its full history, on their own machine, acting as a backup. This means that you can work on your code offline, perform common operations faster, and collaborate with others more easily.
Git belongs to the category of DVCSs.
Basics of Git
Snapshots and Integrity
To keep track of changes in the code, Git uses snapshots, called commits. Snapshots are informal photographs of your code that capture its state at a particular moment.
When committing, Git takes a picture of all your files and stores a reference to that snapshot. If a file has not changed, the snapshot contains a link to the previous one.
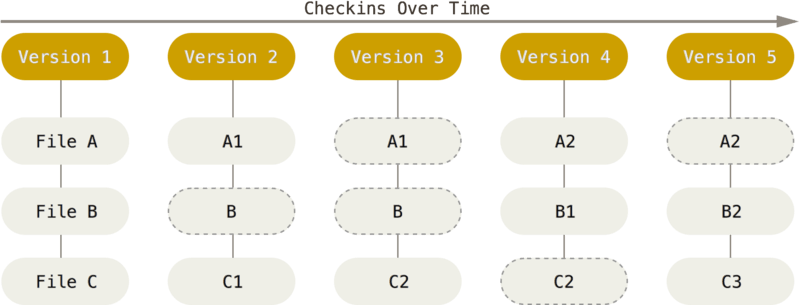
You perform most operations locally; you have a complete copy of the repo on your local machine, so you can do most of your work without remote connection.
By verifying that the snapshots are not corrupted or tampered with, Git also ensures your code’s integrity. It check-sums everything before storing it and then refers to it by that checksum. Git will detect any data corruption. It uses SHA-1 hash to ensure integrity, which looks something like this:
“24b9da6552252987aa493b52f8696cd6d3b00373”
File Locations
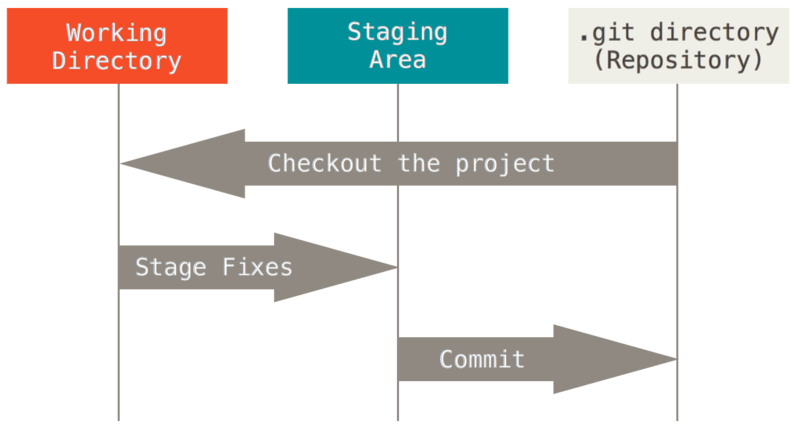
A file can be located in three different logical locations: a working directory, a staging area and a repository. These are three important concepts to understand when using Git. Here is a brief description of each one:
- The working directory is the folder where you have your source files that you can edit, delete, or create. It is also where the hidden .git folder is located, which contains the Git repository. The working directory is also called the workspace or the work tree.
- The staging area is a file in the .git folder that stores information about what will go into your next commit. It is also called the index or the cache. You can add files to the staging area and remove them. The staging area lets you selectively choose which changes you want to commit.
- The repository is the collection of files and folders that Git tracks and manages. It includes the history of all your commits, branches, tags, and other references. You store the repository in the .git folder of your working directory, and you can also copy it to a remote server like GitHub for backup and collaboration.
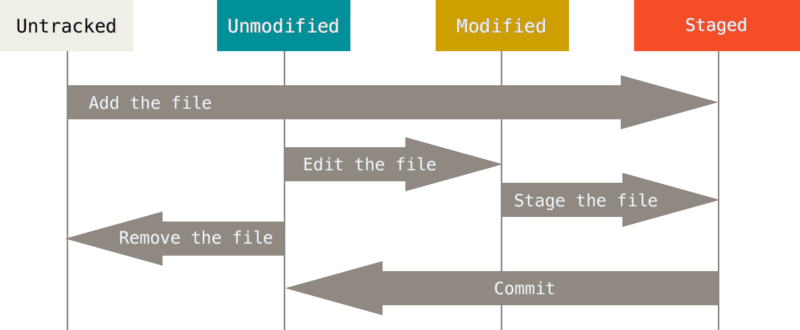
File Stages
Throughout the Git file lifecycle moved to beginning of sentence, files change their status, from being untracked to being committed. There are four main stages in the git file lifecycle:
- Untracked: this is the initial stage of a file that is not tracked by Git. It means that Git does not know about the existence of the file and does not record any changes made to it.
- Staged: This is the stage of a file that has been added to the staging area. It means that Git knows about the file and is ready to commit it to the repository to store its changes.
- Modified: This is the stage of a file that has been changed since the last commit, but has not been added to the staging area yet. It means that Git knows about the file, but does not record the changes made to it.
- Committed: This is the final stage of a file that has been committed to the repository. It means that Git has recorded the changes made to the file and has stored them in the Git directory.
The following diagram illustrates Git file lifecycle:
Branches
Git branches are a way of creating different versions of your code that can be worked on independently and merged later. They are useful for developing new features, fixing bugs, or experimenting with different ideas without affecting the main branch of your project. Branches are very fast and lightweight, as they only store the differences between the commits, not the entire files. Branches are one of the most powerful and popular features of Git, as they enable you to work on multiple tasks simultaneously and collaborate with others more easily.
Internally, a branch is a lightweight movable pointer to one of the commits. The default branch name is main. The HEAD pointer points to the branch you are currently working on. If you don’t create any branches, it will always point to your main branch.
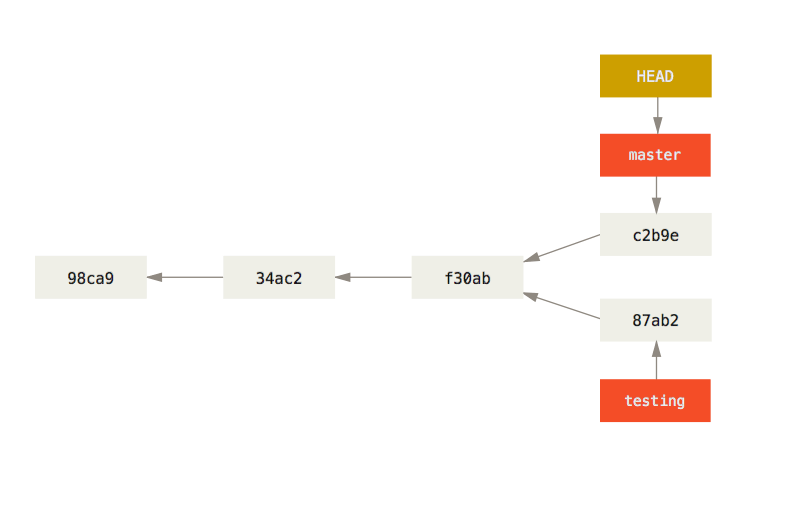
If you change your working branch, then the HEAD pointer will point the local branch you are working with.
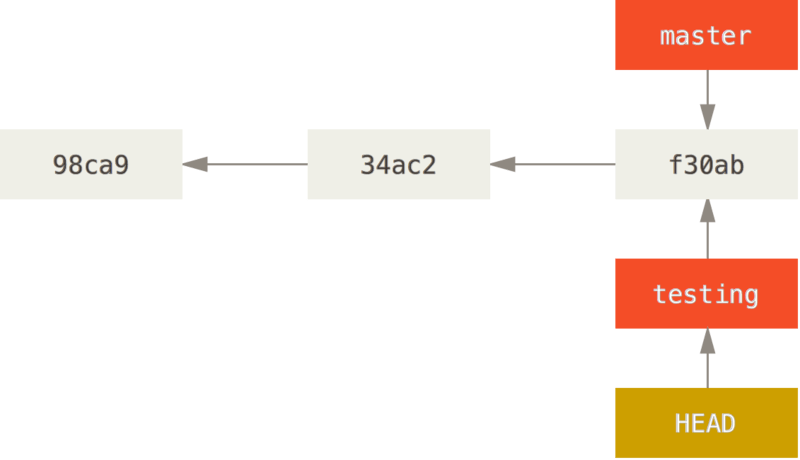
You can merge your branch to the main one to apply its changes when you finish developing it.
Remote Repositories
Remote repositories for Git are versions of your project that are hosted on the internet or network somewhere. They allow you to collaborate with other developers and share your code with them. You can have multiple remote repositories, each with a different name and URL. Remote repositories are one of the key features of Git that make it a powerful and popular version control system.
Some examples of remote repositories for Git are:
- GitHub: GitHub is a web-based platform that hosts millions of git repositories for open source and private projects. You can create an account on GitHub and upload your code to a public or private repository. You can also fork other people’s repositories, which means creating a copy of their code that you can modify and merge back. GitHub also offers features such as issue tracking, code review, pull requests, wikis, and more
- Bitbucket: Bitbucket is another web-based platform that hosts Git repositories for software teams. You can create an account on Bitbucket and upload your code to a public or private repository. You can also collaborate with other developers using features such as pull requests, code review, pipelines, and more. Bitbucket also integrates with other tools such as Jira, Trello, Slack, and more
- GitLab: GitLab is a web-based platform that hosts Git repositories for software development and operations. You can create an account on GitLab and upload your code to a public or private repository. You can also collaborate with other developers using features such as merge requests, code review, CI/CD, security scanning, and more. GitLab also offers self-hosted options for enterprises and organizations
If you want to see a real application of Git used in a remote repository, check out this blog by Sofia Pierini.
References
Pro Git Book: https://git-scm.com/book



