Welcome to the continuation of our exploration of database optimization techniques. If you haven’t already, be sure to check out our previous blog post on Data Normalization, where we delved into the art of structuring databases for efficiency. In this sequel, we’ll unravel the world of Data Denormalization and compare it with its counterpart, data normalization.
What is Data Denormalization?
In essence, data denormalization is a database design technique that intentionally introduces redundancy into a database table. While our previous discussion on data normalization focused on minimizing redundancy and dependency, denormalization takes a different approach. It seeks to optimize query performance by storing redundant data and simplifying the structure of relational databases.
Denormalization is particularly prevalent in Online Analytical Processing (OLAP) databases, where complex queries and reporting are common. By denormalizing certain parts of the database, OLAP systems can achieve significant performance improvements in data retrieval, which is crucial for timely and efficient decision-making.
So, let’s revisit the core concepts and advantages of denormalization in the context of database optimization.
Advantages of Denormalization
The benefits of denormalization are evident in certain scenarios:
- Improved Query Performance: Denormalized tables can lead to faster query performance by reducing the need for complex joins and aggregations.
- Simplified Queries: Queries on denormalized tables tend to be simpler and more straightforward, making them ideal for applications with real-time data access requirements.
- Reduced Joins: Fewer joins are required to fetch relevant data from denormalized tables, resulting in lower computational overhead and quicker response times.
- Enhanced Read Operations: Denormalization can be particularly advantageous for read-heavy operations, as it minimizes the complexity of joins during data retrieval.
- Suitable for Analytics: Denormalization is well-suited for analytical tasks as it simplifies data structures and improves query performance, making it ideal for complex data analysis and reporting needs.
Disadvantages of Denormalization
The contras of denormalization are also important to explain:
- Larger Table Sizes: Denormalization often results in larger tables due to the storage of redundant data. This can lead to increased storage requirements and higher hardware costs.
- Increased Storage Costs: Storing redundant data consumes more storage space, which can translate into higher storage costs, particularly in scenarios where storage is a significant expense.
- Possibility of Data Anomaly: Introducing redundancy in denormalized data can increase the risk of data anomalies and inconsistencies. Maintaining data integrity becomes more challenging, as updates or changes must be synchronized across multiple instances of the same data.
- Less Flexibility: Denormalized tables may not be as flexible as normalized ones when it comes to accommodating changes in data structures. Altering denormalized tables to accommodate new data requirements can be complex and time-consuming.
- Insert & Updates can be Complicated and Expensive: Modifying denormalized data during inserts and updates is often more complex and costly than with normalized data. Maintaining consistency across redundant data may demand extra programming and validation checks, amplifying the intricacy of these operations.
Comparing the Ideas
| NORMALIZATION | DENORMALIZATION |
| OLTP Systems | OLAP Systems |
| Removed Redundancy | Added Redundancy |
| Reduce Inconsistency | Potential Inconsistencies |
| Requires More Joins | Less Joins |
| Complex Data Model | Simpler Data Model |
| Faster Data Writes | Faster Data Reads |
The table illustrates that Data Normalization suits OLTP systems by eliminating redundancy, reducing inconsistencies, and maintaining data integrity through complex data models. This approach prioritizes data accuracy over query performance, rendering it appropriate for systems with frequent data updates.
Conversely, Denormalization suits OLAP systems by introducing redundancy to simplify data models, reduce join complexity, and enhance query performance. However, it can introduce potential inconsistencies. Denormalization prioritizes query performance, proving valuable for systems with complex data analysis and reporting needs.
The choice between normalization and denormalization hinges on the specific requirements of the system, striking a balance between data accuracy and query efficiency.
An example of Data Denormalization
In this section, we’re delving into denormalization, the complementary concept to data normalization discussed earlier on our blog.
Let’s start with a well-structured, normalized database in 3rd Normal Form (3NF), encompassing tables for orders, customers, order details, burgers, and burger prices.
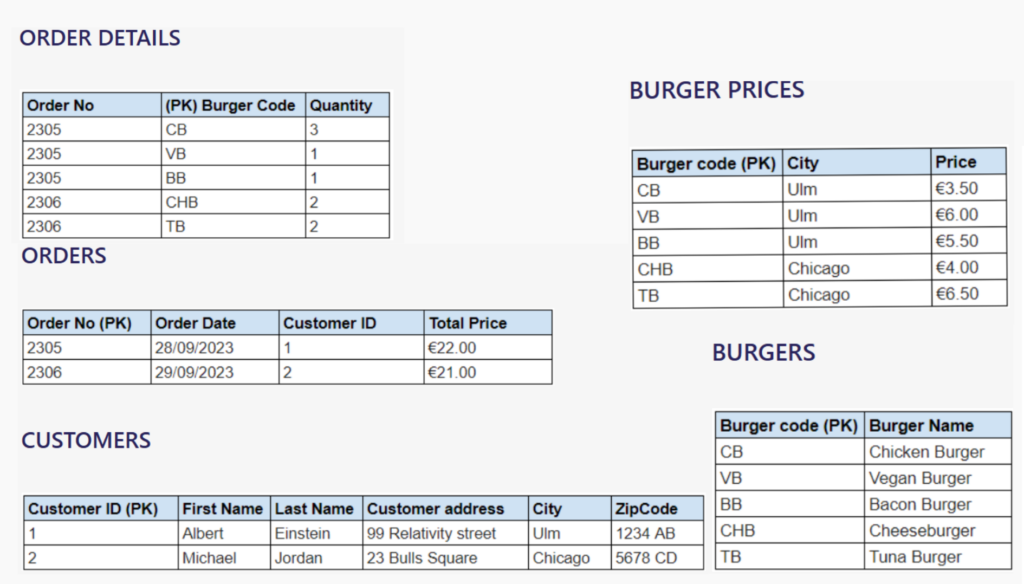
Now, let’s embark on the denormalization journey, aimed at simplifying data retrieval using just customer information. We achieve this by performing a series of JOIN operations:
- JOIN Customer with Orders
- JOIN Orders with Order Details
- JOIN Order Details With Burgers
- JOIN Burgers With Burger Prices
And the final table is:

In this single denormalized table, we’ve combined all the necessary information from the entire database. For instance, a query to retrieve a customer’s order history, including details about the ordered burgers and their prices, becomes a straightforward task, requiring only a single query. This streamlined approach enhances query efficiency, providing users with faster access to comprehensive data.
To sum it up, denormalization simplifies data retrieval and boosts query performance by consolidating information into a single table. However, it also introduces data redundancy and update complexities.
Therefore, the choice to denormalize should be made thoughtfully, keeping your application’s needs in mind while striking the right balance between performance and data management.



