MATCH_BY_COLUMN_NAME vs Variant data type
I found myself having to insert files from my device into my database.
The final aim of the process was to obtain a table with the data organized in columns that had their own name and could then be queried in a simple manner via queries.
The files in question were of type json.
COPY INTO
The copying process consists of the steps we see in the image: load the data into a stage and then bring it into the table. I used a tabular stage (if you want to read more about stages read here and if you are interested in loading process read here).

However, copying can be done in different ways, I have explored two of them.
In loading the files I used a file format with the following characteristics
- type = json
- strip_outer_array = true
The first specifies the type of semi-structured data.
The second allows access to the individual fields that make up each record of type json, if this flag were not set to true the json file would be unloaded but would be seen as a single block inaccessible in its sub-levels.
For more details on file formats read here.
First Way – VARIANT Type
The first option was to create a table with a single column of variant type. You can learn more about this variant type by reading this article.

I then executed the copy via SnowSQL.

By using the Variant type column, I therefore obtained, for each record, a single row containing all the concatenated fields, separated by the appropriate characters that make their indentation explicit.
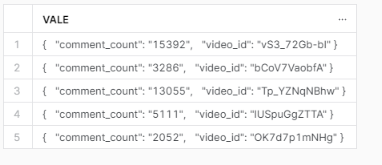
Subsequently, in order to create the table structured in columns, I had to access the fields of the json as I show in the following figure (not exactly an immdiate thing).
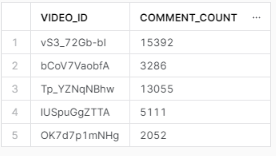
The process was this:

The result was this:
Second Way- MATCH_BY_COLUM_NAME
The COPY INTO, the command that actually copies the data into the table, has MATCH_BY_COLUMN_NAME among the selectable options.
By default, this type of coupling is not active.
If it is specified instead, this option can have two possible values:
- CASE SENSITIVE: the column name in the source file must be identical to that in the target table, including upper and lower case.
- CASE INSENSITIVE: the coupling of fields in the source file-columns in the table is case-insensitive.
I chose the latter to avoid mismatch due to ‘Case’ errors.
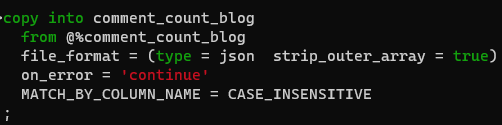
Copying made in this way does not require matching on the numbering of columns: I can select only a part of the columns without incurring errors. For example in my case I had some columns in the file on my device that were not business relevant and I simply did not include them in the table.
The table statement, in this case, was this:

The result after copy into is this:
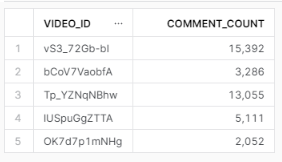
Conclusions
In my case, the results obtained by following the two different routes were identical.
But having to analyse the different strategies, I would like to make these observations:
VARIANT is undoubtedly more flexible, it leaves open horizons on the subsequent processing to be done on the data. It allows us to draw on data of any type (consistently with what is specified in the file format) without worrying about the number of columns or their names.
MATCH_BY_COLUM_NAME saves the trouble of subsequent parsing of the table fields and of the column data types but requires prior knowledge of the columns and their names. A table must therefore be created a priori that can be matched with the data we download.
For more interesting articles on the world of data read our blog!



