Data storage is a critical component of any database system. When dealing with large amounts of data it is unthinkable to assume having to manually enter information – row by row – for each table contained in a database. Every RDBMS has now developed its own way to speed up the insertion and updating of data within its own entities.
Snowflake does not offer you to simply drag and drop files: it’s easy to say there are security issues involved. Moreover, the system would not know in which table to put which data.
However, as a cloud-based SaaS, allows you to import or export data through files that can be contained both in other cloud storage systems and in directories saved locally. Regardless of whether the data is stored, the location of the physical external or internal space where the data is saved goes by the name stage.
Stages
Let’s properly define what a stage is. A stage is a container where data files are stored (i.e. “staged”) so that the data contained in them can be loaded into tables.
Similarly, a stage constitutes the physical space where data from database tables can be saved, ready to then be exported to a terminal or other platforms.
Let’s classify them for categories.
External Stages
As suggested by the name, the files are stored in an external location that is referenced by the stage. Currently, Snowflake supports three different cloud platforms:
- AWS S3 bucket
- Azure Containers
- GCP Cloud storage
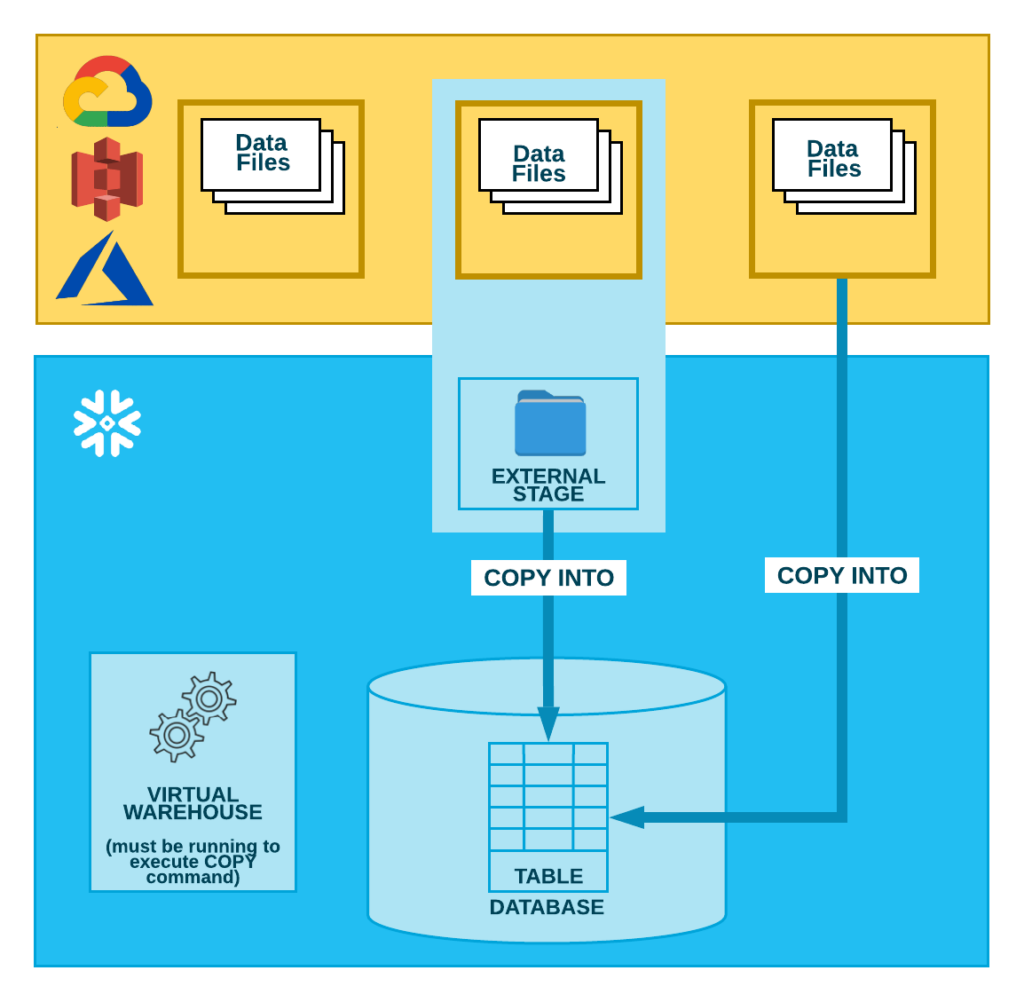
External stages can be created directly from a Snowflake worksheet. As for many other objects, their creation is pretty simple. Here, we provide an example:
# Create in Snowflake an external stage that links to an AWS S3 bucket:
CREATE STAGE AWS_stage
FILE_FORMAT = (TYPE = csv)
URL = 's3://example_bucket/snowflake/'
CREDENTIALS = (AWS_KEY_ID = '<key_name>'
AWS_SECRET_KEY = '<bucket_pwd>'
);
# Check the files attached to an external stage with "@":
LIST @AWS_stage
It is pretty intuitive that, to create a stage, it is just possible to define its name, the type of format the file that will be loaded will have (if all of the same type), the URL from where to take them and the credential to have access to them (if necessary). More specific settings can be found at this page.
Internal Stages
These stages link to directories that are hosted on your Snowflake account. In order to put files in them, they can be accessed from your local machine through SnowSQL (check our other blog).
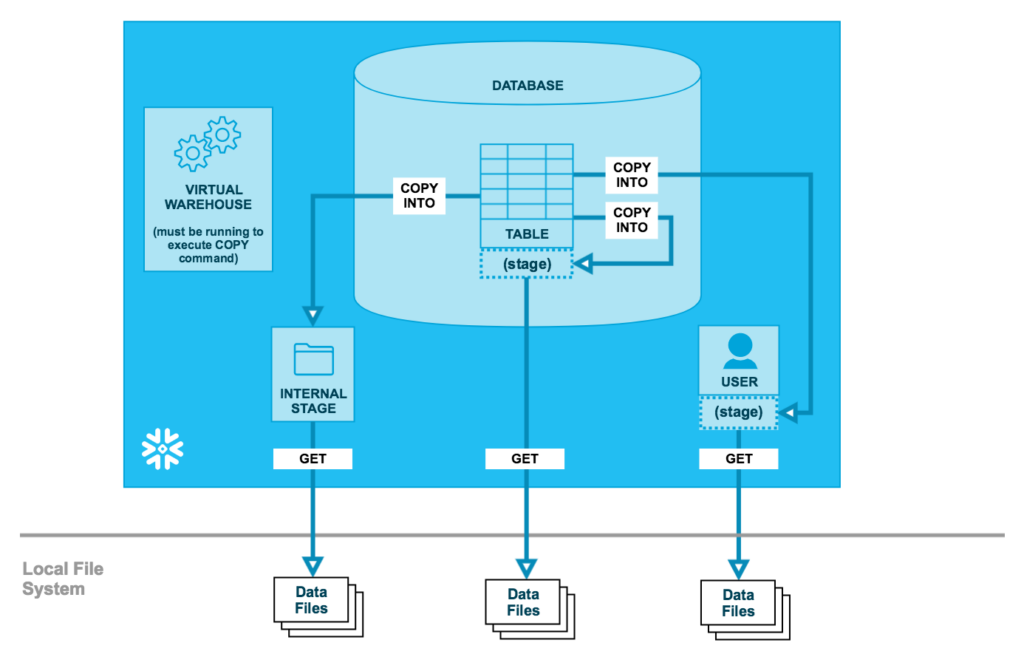
They are classified in 3 different categories.
The first two are:
- User Stage: every user of the account has its own default stage where to load files. This is where Snowflake stores all the worksheets created by the user. Each user can access only its own user stage but, from there, the data contained in the files can be moved in whatever table the user has privileges on.
- Table Stage: every table has its own preparatory stage. It can be accessed by all the users that have privileges on the table, but the data in the files of this stage can be loaded only in the table they belong to.
It’s fair to state that User Stages are not a suitable option if files needs to be accessed by multiple users. Similarly, Table Stages are not meant to store files whose data needs to be loaded into multiple tables.
These two defined only as “permanent stages”. This is beacause they are allocated by default to an associate object, thus impossible to alter or drop.
(In truth, there is a quibble for tables stages. If these stages are connected to a temporary table, they will get erased at the end of the session.)
The third category is nominally what we refer to when we normally talk about internal stages:
- Named Stage: it is the most flexible object for data loading, since it overcomes the limitations of both the other internal stages.
It has to be manually created and saved on a database level. They can be both permanent or temporary (session-based).
Luckily, the syntax to create it is the exact same used for the external stages. However, unlike the external one, it does not need a URL of reference.
It must be created by a user with an appropriate role. All users that are granted roles with the right privileges can access it and the data can be loaded potentially in all the tables (again, according to privileges and rights).
We specify that, for all stages, it is possible to store files in different folders whitin them depending on your need.
Here we show how to access the content of these stages:
# Check the files attached to a table stage with "@%":
LIST @%<Table_name>
# Every user can check the files attached to its user stage with "@~":
LIST @~
# As for the external ones, check the files attached to an internal named stage with "@":
LIST @<named_stage>
To wrap up
In conclusion, we have decided to close this article providing a quick and visual summary of the stages. We hope it can help.
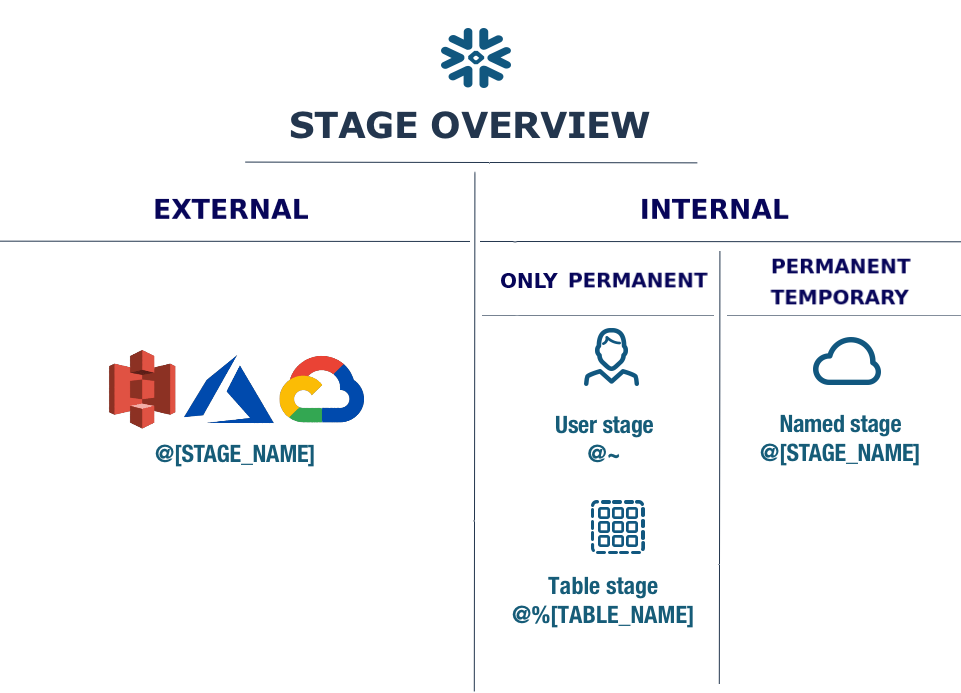
Want to know how to put in/take out files from a stage? And then, how do data reach the tables? Read the next chapter.
Have questions about data? Be sure to check our blog.



