Create an effective data pipeline by following this quick and easy introduction to Dynamic Tables.
Last week I explained how tasks are a powerful tool when it comes to creating a continuous data pipeline—if you’d like to learn more about that, check it our here! This week I would like to continue this theme by exploring the power of dynamic tables.
dynamic tables
Essentially, dynamic tables materialize the result of a specified query.
As we learned last week, it is possible to set up a task to automatically update a table—in fact, we saw that this is one of their greatest advantages. But using a task to update a table creates two distinct entities: the task on the one hand and the table on the other. That means two places where the data pipeline might break down. Which is to say, two potential problems.
Dynamic tables simplify this process by unifying these two entities into one: a table that is defined by a query. The query re-executes when a specified amount of time has passed, keeping the table updated. To create a dynamic table, simply run the following command on a Snowflake worksheet, with your own variables:
CREATE OR REPLACE DYNAMIC TABLE mydynamictable
TARGET_LAG = 'desired_time_lag'
WAREHOUSE = mywharehouse
AS select_statement_defining_my_tableWhere:
- The target lag keyword specifies how often you want your query to refresh the table with new data. If you create your table at 9:18 with a target lag of ‘1 minute’, your table will refresh at 9:19, 9:20…
- The warehouse keyword specifies which virtual warehouse your table will use to execute its query. You can learn more about virtual warehouses here.
- The query defining your dynamic table comes after the ‘AS’.
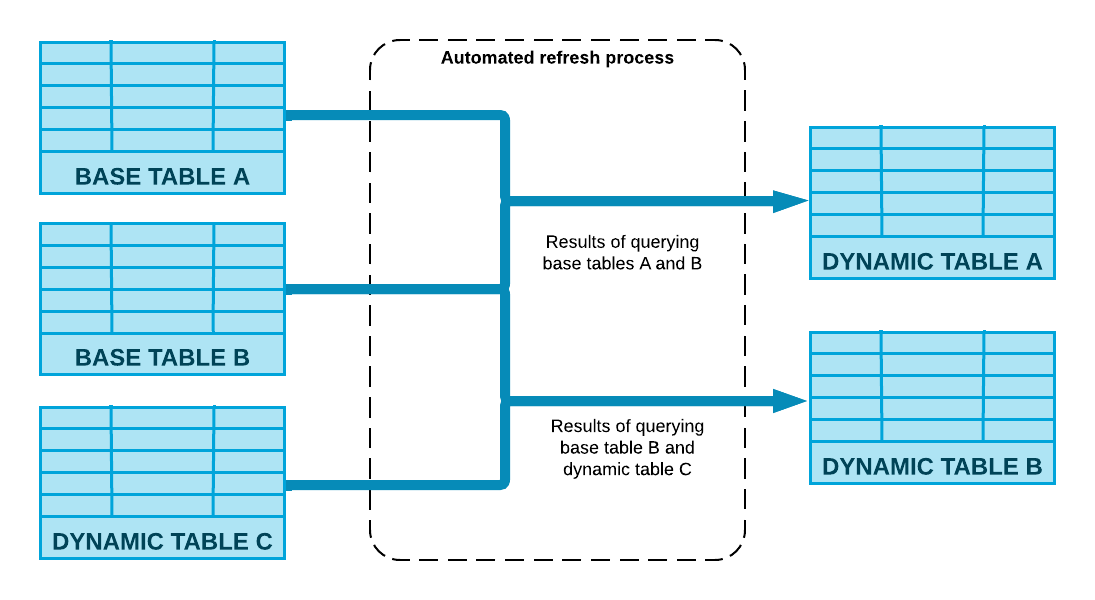
Dynamic table pipelines
You have the flexibility to establish a chain of dynamic tables that query other dynamic tables, creating an interconnected data pipeline.
Consider a scenario where your data pipeline extracts data from a staging table and uses it to update separate dimension tables for customer, product, and date-time information. Additionally, the pipeline updates an aggregate sales table based on the dimension tables.
You can configure the dimension tables as dynamic tables that retrieve data from the staging table. Subsequently, you can set up the aggregate sales table as a dynamic table that queries the dimension tables.
Conclusion
Dynamic tables are an easy and functional way to simplify data pipelines. Whereas before you had to set up a task to update a table, now you can create a table that is updated automatically. Moreover, you can chain together dynamic tables to get the most out of them. This makes them an incredible tool at the disposal of the BI developer.




One Comment