When talking about Big Data, we cannot escape from their very fundamental characterization of 3 (4, 5 or as many as you like) V. Regardless of how many V you there will always be one related to Velocity. Indeed, the peace at which we generate data nowadays is nothing comparable to what we did in the past, and it is estimated that 90% of the world’s data was generated in the last two years alone (https://explodingtopics.com/blog/data-generated-per-day). Sometimes, applications need to be able to process data as soon as they are created. We usually refer to this as streaming processing.
Apache Kafka is one of the most useful tools for handling real-time data. As such, Snowflake developed a connector which allows it to directly ingest data from Kafka. In this article, we give an overview of how those two tools work together and the benefits coming from this interaction.
Why Kafka
Many real systems generate information continuously in such a way that data loses value if we cannot process it on the fly. Let’s think about Netflix and how it tries to recommend the exact TV show or film we would like to see. Of course, it learns our preferences by looking at the history of the programs we saw in the past. But, it needs more information to guess what we want to see now. Are we sad and searching for some dramas, or do we want some comedy to lift morale? Well, if only Netflix could account for what we are searching for in real-time… Guess what, it can thanks to Apache Kafka!
How Kafka handles data streaming
Kafka allows the management of data streaming through a publish-subscribe messaging system. This enables seamless communication between producers and consumers of data streams. We can think of the Kafka architecture as made up of three layers:
Producers. Those represent any application that generates data and send them to Kafka. Producers represent the source of data streams we want to capture and process through Kafka.
Topics. As soon as producers send data to Kafka, those data have to be stored somewhere waiting for them to be used (consumed) by applications called consumers. Topics make it possible to organize the staging area that retains data. In such a way it is easier for consumer applications to access only the data they need.
Consumers. Each application pulling data from Kafka topics is known as a Kafka consumer. A consumer decides when to get data from Kafka so that the processing speed can match or not the peace at which producers push data into Kafka. Moreover, a consumer can subscribe to one or more topics to access the specific data it has to process.
How to leverage Kafka with Snowflake
The usefulness of leveraging data streams can be further improved by integrating real-time information with other already available company data. However, this may not be as straightforward as it seems as it requires properly processing real-time data to join them with more structured information usually available inside a data warehouse. Snowflake is one of the latest yet successful cloud-based platforms enabling data warehousing capabilities and it natively provides solutions to smoothly exploit Kafka features.
Kafka connector
The Kafka connector is designed to run in a Kafka Connect cluster to read data from Kafka topics and write the data into Snowflake tables.
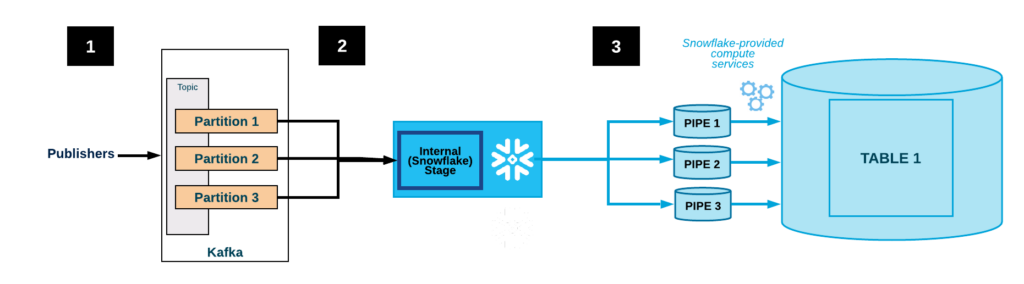
Snowflake interacts with Kafka by moving data staged in Kafka topics to a different staging area internal to Snowflake. The Kafka connector accomplishes this task and monitors the ingestion process eventually sending error messages.
Overall, Snowflake assigns one table per topic, and each Kafka message translates into a row in the corresponding table. As soon as data are correctly ingested they can be processed within Snowflake and seamlessly integrated with other tables.
Conclusion
The integration of Apache Kafka and Snowflake through the Kafka Connector streamlines real-time data management, enhancing analytics capabilities. By leveraging Kafka’s streaming features and Snowflake’s data warehousing capabilities, organizations can process and analyze data in real-time, driving informed decision-making and staying competitive in today’s fast-paced landscape.



