
Looking to automate your workflow? Let me introduce you to the beautiful world of tasks. I’ll be your guide. Lets begin.
WHat are tasks?
Think of an alarm clock. Now think of a device – say, a washing machine – connected to that alarm clock, so that when the alarm goes off, the machine goes off – in this case, washes your clothes. That is, essentially, the structure of a snowflake task: 1) The alarm goes off; 2) something happens. Setting up a task means choosing when the alarm will go off and what will happen as a result.
Why tasks?
Unlike in real life, in Snowflake tasks make our lives easier. We set up a task in snowflake so that we don’t have to do it. This has the obvious benefit of relieving our workload, which is almost always desirable, because it allows workers to focus on doing what machines cannot do. Automation gives you more buck for your money and relives workers of carrying out monotonous tasks, like pushing a button at a specified time.
This is already reason enough. But there are other considerations, specific to the nature of data processes, that make tasks invaluable allies. In order to explain them, I will do a brief introduction to ELT/ETL processes of data integration.
ELT/ETL
Data is a resource – some might say the most valuable resource of our time. And, just like any resource, it needs to be extracted, processed and stored, in order to be put to good use. In terms of data, this process is called ‘ETL’: ‘extract, transform, load’; whereas ‘ELT’ stands for ‘extract, load, transform’. For our purposes, it does not matter whether we choose to think of data as being stored and then processed, or processed and then stored. What matters is that data does not come out of thin air; that there is a process behind its useful application, involving a lot of different tools and actors. It is at least part of the job of a BI developer to supervise and carry out the successful completion of this process.
Below is a more detailed diagram of this bare-bones explanation:
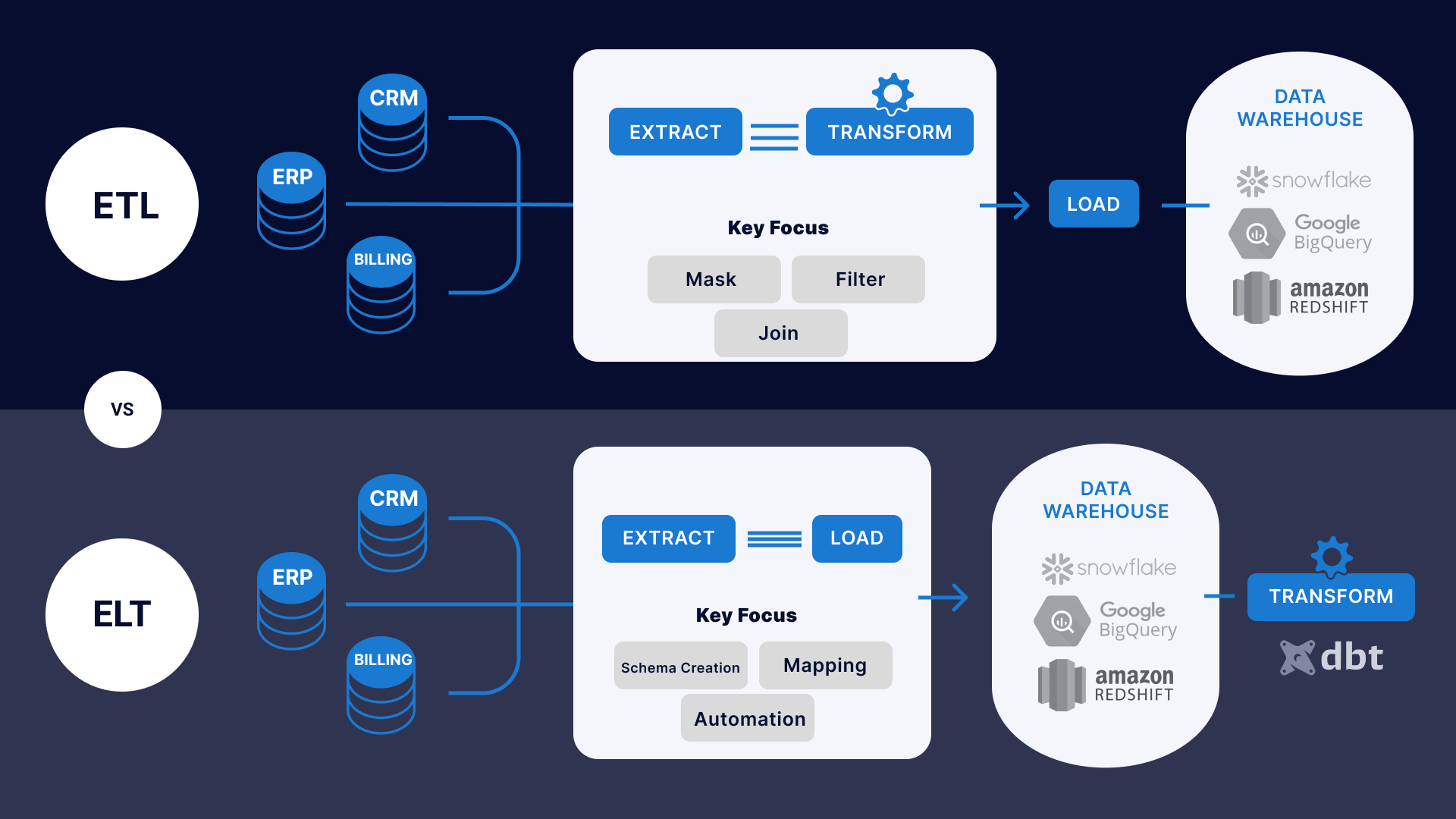
It used to be that people would have to go back and forth between their house and a well in order to get water. Now we have pipes, water treatment plants, and tanks to store water. In this analogy, tasks are like the pipes and water treatment plants: They are the infrastructure that ensures that we don’t have to go back and forth to the well, and that we can trust the cleanliness of our data.
so why tasks, again?
Essentially, tasks get rid of human error, or rather they minimize it by ensuring that it takes place in the same way every single time. Once I get my SQL script to run the way I want once, I can rest assured that it will run that way indefinitely – that is, until something is changed. This achieves two important goals:
- Consistency: my data will have the same characteristics – column names, definitions, transformations – no matter what. This ensures that when we pass the bucket to the data analyst, they can know what to expect; and that they won’t make calculations with data that has been inconsistently labeled or processed.
- Regularity: my data will be predictably available at specific times. You know why this matters if you take public transport: no one likes a delayed bus or train. The data analyst can go about their business knowing that at some specified time they will have a fresh batch of data waiting for them.
great! how do I use them?
simple time intervals
To create a task, you simply need to run the following command:
CREATE TASK mytask
WAREHOUSE = mywarehouse
SCHEDULE = 'desired_time_interval'
AS desired_querySay we want to run our task once every minute. We would write, between quotes ‘1 minute’ in place of ‘desired_time_interval’ above. If we activated that task at 9:18, it would run at 9:19, 9:20…
CRON based intervals
But what if we want our task to run, not every x amount of time, but only on a specific day, say, every five minutes each Sunday, Los Angeles time? To do so, we can simply use CRON expressions, which allow us to be much more granular in our time specifications. Instead of ‘desired_time_interval’, we would write ‘USING CRON 5 * * * SUN America/Los_Angeles’.
CRON expressions might seem complicated, but there are loads of tools that help us translate ordinary language into CRON expressions, such as this one: https://crontab.cronhub.io/.
task chains
Now, lets say we want to create a task to load clean data into a table. We would not want our task to execute before our data has been cleaned, the reason being twofold: 1) an error is likely to arise, for our table will be expecting data with different characteristics from the ones that it had before cleaning; 2) even worse, we might end up mixing clean and unclean data without realizing, thus tainting our analysis. Do we need to rely on a time schedule to ensure that our task will execute?
No. We can choose to set up a task to execute only after another task has executed! We simply need to use a different keyword: ‘after’ rather than ‘schedule’, and specify the task we want our task to be set off by. In our example, it would look like this:
CREATE TASK clean_data_task
WAREHOUSE = mywarehouse
SCHEDULE = 'desired_time_interval'
AS query_to_clean_data
CREATE TASK load_clean_data
WAREHOUSE = mywarehouse
AFTER = clean_data_task
AS query_to_load_clean_dataAnd that’s it! Now we have ensured that data will only be loaded once it has been cleaned.
conclusion
This simple snowflake tool can be stacked to automate processes, make them run in parallel, and generally make your life a whole lot easier. Once you get the hang of it, there is virtually no limit to how much you can automate your processes, or how wide your task net can go. I hope you liked this little tutorial and explanation.
Sources and resources
https://hevodata.com/learn/snowflake-tasks/
https://docs.snowflake.com/en/user-guide/tasks-intro
https://www.youtube.com/watch?v=165hXZ_o4Vk



