In this post I will introduce you to the main components of the Snowflake Architecture. I will explain what it means for Snowflake to have a hybrid architecture and why that is a good thing. Then I will go into the different layers that make up that architecture and the purposes they serve. Finally, I will explain the main concepts associated with each layer. Lets begin.
Shared-disk vs Shared-nothing architectures
Most databases have a shared-disk architecture. In order to scale up such architectures, the memory, the disk and the number of CPUs in the system must increase. But there is a limit to how much these can increase within a single system.
That’s where the shared-nothing architecture comes in. In it, each node has its own processing power and its own allocated slice of data. This provides massive parallelism, as it distributes the data and processing evenly across the nodes.

But there is one critical limitation to shared-nothing architectures: they cannot scale storage and compute independently.
Snowflake’s hybrid architecture
The shared-disk architecture can only scale up to a certain point, whereas the shared-nothing architecture requires storage and compute to be scaled up together.
This is where Snowflake’s hybrid architecture comes in: it stores data in a shared and centralized manner while still being able to run one or more compute engines.

This means that, if you need more processing power at any given time, you can increase the size of your compute engines or add additional engines. These are called virtual warehouses. Snowflake uses them for query processing and data loading jobs. The data is stored on inexpensive cloud storage and can be scaled independently and almost infinitely, using micro-partitions.
The three layers of Snowflake Architecture
- Database Storage: Cheap cloud storage on AWS, Azure or Google Cloud.
- Query Processing: Primarily composed of virtual warehouses.
- Cloud Services: The brain of the whole operation.
Database storage layer:
Data loaded into Snowflake is stored as files on the cloud-based object storage. Such files are immutable, which means that they cannot be updated once written, but only appended.
Query processing layer:
Compute layer in charge of executing queries and processing jobs on stored data. There can be multiple compute clusters running simultaneously for a single Snowflake instance. Each compute cluster is referred to as a virtual warehouse:
- While they are independent of storage, they access the same shared data.
- They can have different configurations and purposes.
- They can be started and shut down as needed, thus incurring costs only when active.
This is what makes Snowflake a multi-cluster, shared-data architecture.
Cloud services layer:
All access to a Snowflake account is through this layer. It manages metadata on storage, users, roles, security, etc. Additionally, all queries are parsed and optimized in this layer, before being dispatched for execution. Finally, it ensures ACID compliance on all its transactions:
- Atomicity
- Consistency
- Isolation
- Durability
Data sharing, cloning and exchanges are all managed through the cloud services layer. It can do this because it uses metadata operations that don’t actually require the data to be moved.
Database Storage Layer: Micro-Partitions and Clustering
Files in the cloud object storage are transparent. This means that they cannot be accessed or seen by users.
When a table is created and loaded with data, the table’s metadata in the cloud services layer stores the location of the underlying files. When a user queries a table, it is the query processing components in the cloud services layer that are responsible for accessing the correct underlying files that correspond to the table.

As mentioned previously files stored in the cloud are immutable—they cannot be modified once written. This creates a challenge, for in a database data is constantly updated. Snowflake uses micro-partitioning to solve this problem.
Characteristics of micro-partitions:
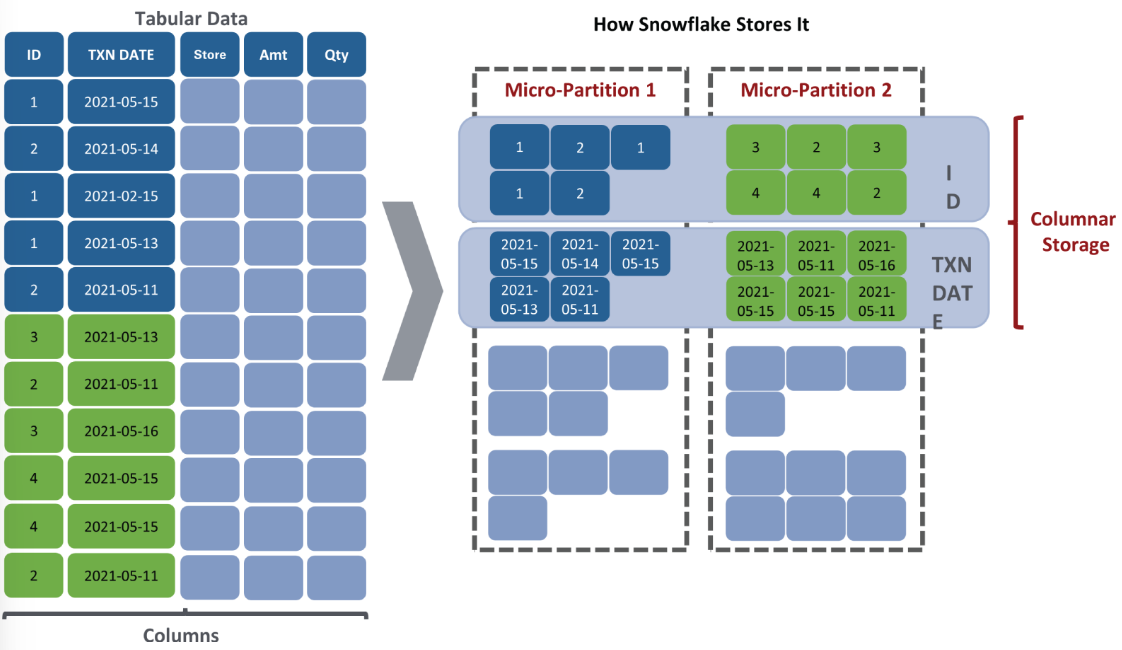
- Immutable: They cannot be changed once created. Hence, loading or updating data results in new micro-partitions.
- Compressed: They are relatively small, each one consisting of 50 to 500 MB of uncompressed data. This allows for the elimination of partitions during query execution, or pruning, which greatly improves performance.
- Can be numerous: The number of micro-partitions for a table depends on the amount of data in that table. For a very large table, there can be hundreds of millions of micro-partitions.
- Columnar: Each column is stored in a columnar format within each micro-partition. This optimizes queries by retrieving only the referenced columns. Both the micro-partition and the columns inside the micro-partition are compressed.
- Overlap: There can be two partitions for the same column values and overlaps between partitions for different column values.
- Ordered by arrival: Micro-partitions are added to a table as data arrives to that table. This means that identical values for a column may be stored in different physical partitions.
- Metadata: Column values are spread across partitions. Hence, metadata about ranges is kept in the cloud services layer to ensure efficient query processing. It includes:
- Max, Min and Count
- Number of distinct values
- Other optimization metadata
As a result, Snowflake can intelligently decide which partitions to read when processing a query. Moreover, this means that some queries are answered directly from the metadata, without scanning the whole table, such as COUNT(*).
- Automatically clustered: Snowflake automatically clusters the data as it is inserted into a table. In the case of exceptionally large tables, it might be advisable to manually specify a clustering key to ensure the effective elimination of partitions by the WHERE predicate.
I recommend you visit my colleague Eduardo’s post for more information on the topic.
Query Processing Layer: The Concept of a Virtual Warehouse:
A virtual warehouse is a multi-node compute cluster. It is used to process queries and data loading jobs. To that end, it provides CPU, memory and temporary storage.
Each node in a virtual warehouse is a low-cost virtual machine instance running on the cloud. Each node has its own memory, compute resources and local cache.
Snowflake uses T-shirt sizes to label virtual warehouse size. Snowflake doesn’t share the specific resources available to a single node. But we know that each step in size corresponds to twice as many nodes as the previous size: 1, 2, 4, 8, 16… up to 512 (6X-Large).

Important features of Virtual Warehouses:
- Access shared data: while each virtual warehouse has its own compute, they access the same data associated with an account.
- Can be resized at any time:
- If resized while suspended, the update takes place when resumed.
- If resized while running, the update will only take effect on queries that are not being processed—queued and new queries.
- Billing: credits are billed on a per-second basis, with a minimum billing of 60 seconds. The billed credits per second depends on the size.
- Scaling up: increasing the number of nodes in a virtual warehouse. The charge is not incurred until the nodes are actually used to process queries.
- Scaling down: decreasing the number of nodes in a virtual warehouse. Only takes place when the warehouse is no longer running a query.
- Scaling out: A multi-cluster virtual warehouse dynamically and automatically increases or decreases the number of clusters based on demand. Typically used when queries begin to queue, which happens when concurrent workload goes beyond the maximum resources of a virtual warehouse.
- States:
- Resumed warehouses consume credits and process queries.
- Suspended warehouses do not consume credits or process queries. Suspension only takes place once all active queries have been processed.
- Auto resume automatically resumes the warehouse when a query tries to execute on a suspended warehouse.
- Auto suspend automatically suspends the warehouse after a defined period of inactivity.
References
https://docs.snowflake.com/en/user-guide/intro-key-concepts
https://docs.snowflake.com/en/user-guide/tables-clustering-micropartitions
https://docs.snowflake.com/en/user-guide/warehouses



