Non-relational databases are databases that don’t store data in a tabular schema. When data structure frequently changes, or when workload reaches millions of transactions per second (i.e. you’re dealing with Big Data), you should consider a non-relational database architecture. These databases can be optimized for storage and usage of very specific kinds of data, such as time series data, free-form text data, and data that is best represented on a graph.
The Relational Model
Non-relational databases exist in contrast to relational databases.
In a relational database model, data is stored as related tables. It also often undergoes a process called normalization, which ensures that every table entry is appropriately well-defined. It sounds complicated — because it is! Here’s a schematic diagram of a relational database:
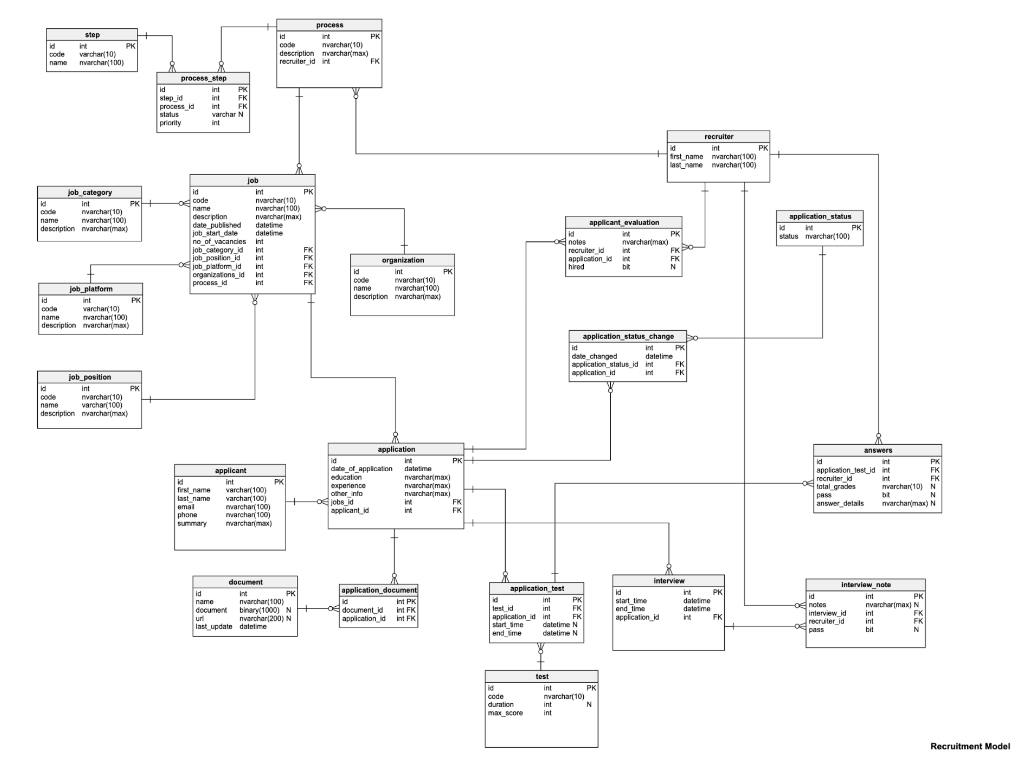
A normalized relational database is a great way to reduce data redundancy and ensure data integrity. Sufficiently trained users would also be able to reliably query such a database to find simple and complex information about the system. Finally, relational databases can support guarantees of ACID-compliance.
In terms of the CAP Theorem, distributed relational database systems tend to provide consistency and availability but not partition tolerance when faced with network failures. (Modern RDBMS’s, however, have been evolving to handle partition tolerance better.)
The Non-Relational Model
Because tables in a relational database adhere to rigid schemas, they tend to be inflexible to changing data structure. Every new structure needs to be translated into a suitable schema and adapted to the database model. Non-relational databases, however can be more flexible and tolerant to the changing structure of data. They can support key-value stores, documents, graphs, and any other file structure you can think of. They can be more suitable to Big Data applications, because their flexibility supports intake of high volumes of data. Because data doesn’t need to maintain a relational structure, it can be easily scaled up and distributed geographically.
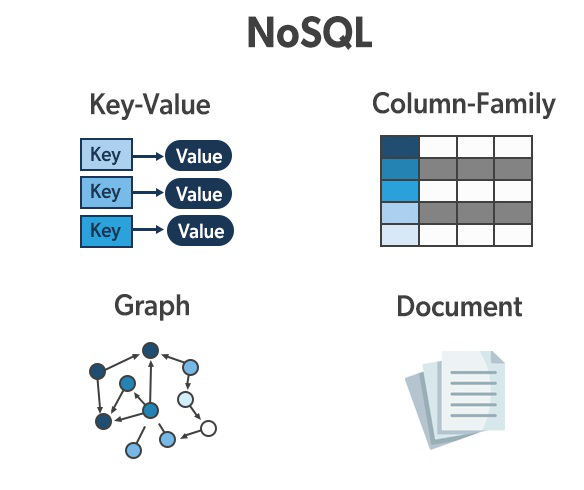
But there are tradeoffs. Abandoning a relational structure and rigid schemas also makes it more difficult to maintain ACID-compliance. Distributed architectures provide great scalability, but sacrifice consistency. Finally, without clear organization of the data, performing complex queries is not as simple task as it would be in a relational database.
Obviously, neither solution is perfect in every circumstance. That’s why a good data architect should understand the advantages and disadvantages of each model.
Thanks for reading!



