In this blog post I will explain what DBT models are and how to use them effectively. For background on DBT, click here; for some background on the role most commonly associated with DBT, analytics engineering, click here. Let’s begin.
The concept of a DBT model
.jpg)
DBT models are .sql files residing in the models folder. These models are essentially SQL select statements, and they do not require any DDL/DML to be wrapped around them. This simplicity allows developers to focus on the underlying logic. In a Cloud IDE, you can use the Preview button to execute the select statement against your data warehouse. This displays results equivalent to the materialized model.
Materializing models
To materialize a model into the data warehouse, you can use the dbt run command in the command line. By default, DBT materializes models as views. However, you can configure them as tables by including the appropriate configuration block at the top of the model file.
Additionally, during the execution of dbt run, the select statement in the model is wrapped in the necessary DDL/DML to build the model as either a table or a view. If the model already exists in the data warehouse, dbt will automatically drop the existing table or view before creating the new database object.
modularity
Modularity is an essential concept in the world of analytics engineering. It allows you to break down the process of building data artifacts into logical steps. With dbt, you can build your final data products using modularity, much like software engineers do when building applications.
For example, you can stage raw customer and order data to shape it before building a model that references both datasets to create a final model, like dim_customers.
Referencing models
The ref macro plays a crucial role in enabling modularity. While models can be written to reference underlying tables and views directly, this can make it challenging to share code between developers. The ref function provides a more flexible way to create dependencies between models that can be shared within a common code base.
This function compiles to the name of the database object based on the most recent execution of dbt run in the specific development environment. DBT also builds a lineage graph that determines dependencies between models and ensures correct ordering, as in the examples bellow.
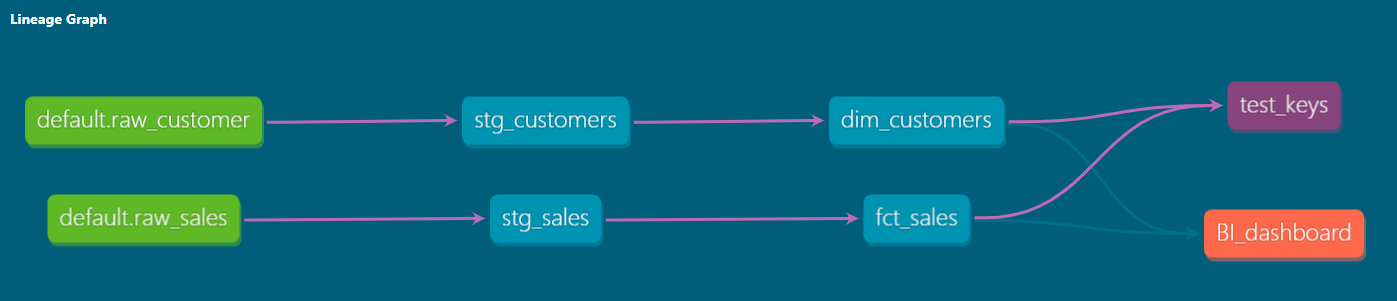
dbt supports various modeling paradigms, including normalized and denormalized modeling. With a modern cloud-based data warehouse, you can adopt an agile or ad hoc modeling technique. dbt gives you the flexibility to build your data warehouse according to your chosen schema, rather than enforcing a specific approach.
Naming
Naming conventions are essential for organizing models in a dbt project. Different prefixes, such as src, stg, int, fct, and dim, help categorize models based on their role and relationship with the data. These conventions ensure clarity and consistency in your project.
Folder structure
When running dbt, it automatically processes all models in the models directory. You can further organize your project using subfolders within the models directory. This structure allows you to select specific folders for execution, making it easier to manage different aspects of your data project. For instance, you can run models within the “staging” subfolder using dbt run -s staging. This organizational framework provides a starting point for designing your own model organization, with the option to create subfolders based on business functions and data sources to suit your project’s needs.
References and further reading
https://docs.getdbt.com/docs/build/models
https://www.getdbt.com/analytics-engineering/modular-data-modeling-technique
https://towardsdatascience.com/how-to-make-your-data-models-modular-71b21cdf5208




One Comment