
Il machine learning (ML) ha dovuto a lungo affrontare un compromesso tra scalabilità e usabilità. Insieme, Databricks e KNIME rimuovono questa barriera: combinando l’infrastruttura cloud su larga scala di Databricks con i workflow visivi e low-code di KNIME, i team possono semplificare la preparazione dei dati, accelerare l’addestramento dei modelli e semplificare l’implementazione.
Il risultato è una potente sinergia che consente ai professionisti del ML e ai data engineer di ridurre la complessità per gli utenti meno tecnici e di sviluppare soluzioni, già pronte per il passaggio in produzione, più rapidamente.
Questo terzo articolo della nostra serie Databricks & KNIME approfondisce il modo in cui le due piattaforme si integrano per creare flussi di lavoro di machine learning scalabili, dalla preparazione dei dati e il feature engineering all’addestramento e alla distribuzione dei modelli, consentendo sia ai team tecnici che agli utenti business di creare soluzioni robuste e pronte per la produzione.
Dalla BI alla GenAI: il percorso finora
Nell’ambito di una serie di quattro blog, stiamo esaminando i modi in cui KNIME e Databricks si integrano per supportare ogni fase del ciclo di vita dei dati e dell’IA.
Nei blog precedenti abbiamo trattato gli aspetti fondamentali di:
-
Business Intelligence. Come KNIME si connette a Databricks tramite connettori sicuri e semplici da utilizzare, consentendo agli analisti di interrogare le tabelle Databricks, esplorare Unity Catalog e mantenere tutta l’elaborazione dei dati all’interno di Databricks.
-
Data Engineering. Come la scalabilità di Databricks e i flussi di lavoro low-code di KNIME possono semplificare la preparazione, il blending e la trasformazione dei dati su larga scala, eliminando i classici silos e ottimizzando le pipeline.
Ora, in questa terza fase, partiamo dalle basi della BI e del data engineering per mostrare come Databricks e KNIME possono collaborare per creare soluzioni nell’ambito del machine learning.
Scalare i flussi di lavoro di machine learning con Databricks e KNIME
Sfruttando la potenza di calcolo di Databricks insieme alla piattaforma intuitiva di KNIME, le organizzazioni possono avvalersi di analisi avanzate e machine learning, semplificando processi complessi e accelerando al contempo l’ottenimento di informazioni utili.
Vi guideremo lungo un percorso in cui potrete imparare come:
-
Collegare Databricks ai flussi di lavoro KNIME, creando una pipeline per l’elaborazione e l’analisi dei dati.
-
Elaborare e analizzare set di dati su larga scala e addestrare modelli ML in modo efficiente utilizzando i nodi Spark visivi di KNIME sui cluster Databricks.
-
Automatizzare i flussi di lavoro o trasformarli in soluzioni implementabili, come data app interattive o API REST.
Seguendo questo approccio, acquisirai la capacità di creare flussi di lavoro ML scalabili e pronti per la produzione che sfruttano appieno le capacità sia di KNIME che di Databricks, senza bisogno di scrivere codice Spark.
Creazione di flussi di lavoro ML in KNIME con Databricks
Un tipico progetto ML passa dall’acquisizione dei dati alla distribuzione:
-
Importa dataset Databricks in KNIME tramite il Databricks Workspace Connector.
-
Pulisci e trasforma i dati utilizzando i nodi visivi e abilitati per Spark di KNIME.
-
Allena il modello in modo scalabile sull’ambiente Databricks e riporta il modello risultante in KNIME per la validazione, explainable AI e messa a punto finale.
-
Salva il modello validato.
Questo ciclo è iterativo, per cui le modifiche alle feature, il riaddestramento e il monitoraggio mantengono la pipeline robusta e riproducibile negli ambienti di sviluppo e produzione.
Ora esploriamo questo processo nel dettaglio, utilizzando un workflow KNIME da guida pratica.
Questo flusso di lavoro fa parte dei corsi gratuiti “Getting Started” disponibili sul KNIME Community Hub: qui è possibile trovare tutto il materiale.
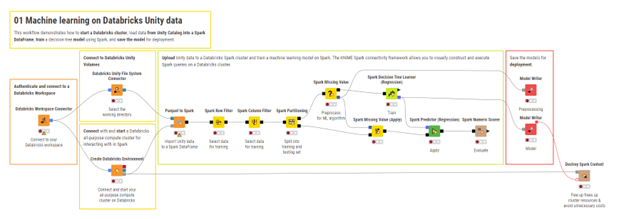
1. Preparazione dei dati e feature engineering
Passaggi fondamentali per elaborare i dati Databricks con Spark in KNIME
Come descritto nel blog Data Engineering, KNIME consente di pulire, unire e trasformare grandi dataset su larga scala con Spark.
Per il machine learning, la stessa metodologia si può estendere per il feature engineering.
Infatti, i nodi Spark di KNIME consentono di connettersi a un cluster Databricks, creare un contesto Spark ed elaborare direttamente i dati Unity Catalog senza dover scrivere codice Spark.
Il flusso di lavoro segue in genere questi passaggi:
-
Crea un contesto Spark con il nodo Create Databricks Environment.
-
Importa tabelle o file Unity Catalog per utilizzarli come Spark DataFrames.
-
Trasforma e modella le feature del modello utilizzando i nodi abilitati per Spark o le pipeline Spark ML.
-
Esporta i dati o le feature trasformati nuovamente in Databricks.
-
Distruggi il contesto Spark per liberare risorse.
Ciò garantisce una pre-elaborazione scalabile per le attività ML, mantenendo i dati al sicuro in Databricks.
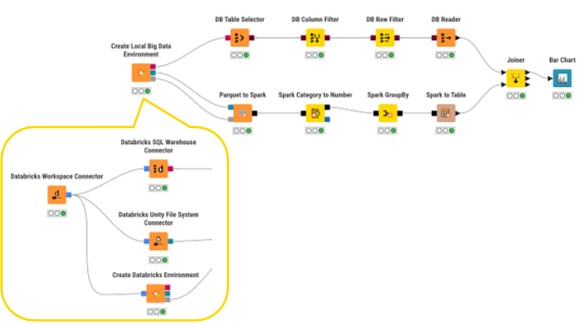
2. Prototipazione dei workflow Spark in locale
Come introdotto nel blog Data Engineering, il nodo Create Local Big Data Environment di KNIME consente di prototipare flussi di lavoro Spark senza utilizzare un cluster Databricks live.
Ciò è particolarmente utile per i test e la convalida, poiché è possibile utilizzare campioni di dati rappresentativi a livello locale.
Dopodiché, una volta convalidati la logica e le trasformazioni, lo stesso flusso di lavoro può essere scalato sostituendo i connettori Databricks, riducendo al minimo i costi di sviluppo e garantendo al contempo la prontezza alla produzione.
3. Addestramento e valutazione dei modelli
Addestramento su larga scala con Spark
KNIME implementa il ciclo di machine learning come paradigma Learner – Predictor:
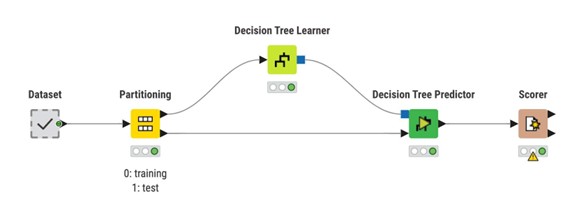
Motivo Learner-Predictor per l’addestramento dei modelli di machine learning in KNIME.
-
Un nodo Learner adatta un modello ai dati di addestramento.
-
Un nodo Predictor applica quel modello a dati non visti.
-
Un nodo Scorer o altri nodi di valutazione misurano le prestazioni del modello.
Questa separazione mantiene i flussi di lavoro modulari e semplifica lo scambio di algoritmi o fasi di pre-elaborazione.
Quando il set di addestramento cresce oltre la capacità di una singola macchina, è altresì possibile utilizzare lo stesso modello Learner–Predictor su Spark e sfruttare la potenza di calcolo di Databricks.

Addestramento di modelli di machine learning in KNIME.
-
Crea un contesto Spark collegato al cluster Databricks.
-
Carica i dati in un Spark DataFrame (da Unity Catalog, Parquet/CSV, ecc.).
-
Partiziona i dati (addestramento/test o addestramento/convalida/test) utilizzando il nodo Spark Partitioning.
-
Applica i nodi Spark Learner (algoritmi Spark MLlib o librerie integrate come H2O).
-
Utilizza i nodi Spark Predictor per eseguire previsioni e misura le performance con i nodi Scorer/metrics.
-
Conserva i risultati (modelli, metriche, tabelle trasformate) nel formato desiderato.
Ciò consente di eseguire i calcoli più pesanti in remoto, ridurre i tempi di addestramento e preservare la riproducibilità.
4. Implementazione del modello
L’addestramento è solo metà del lavoro: la produzione richiede il packaging e la distribuzione del modello.
In KNIME, la logica è la seguente:
-
Salva il modello e gli artefatti di pre-elaborazione con i nodi Model Writer.
-
Assembla un workflow di previsione che carica i modelli, applica la stessa pre-elaborazione e restituisce le previsioni.
-
Metti in produzione il flusso di lavoro:
-
Carica e versiona il flusso di lavoro su KNIME Community Hub/KNIME Business Hub.
-
Seleziona una modalità di distribuzione: pianifica il flusso per previsioni batch regolari, pubblicalo come data app interattiva o esponilo come API REST.
-
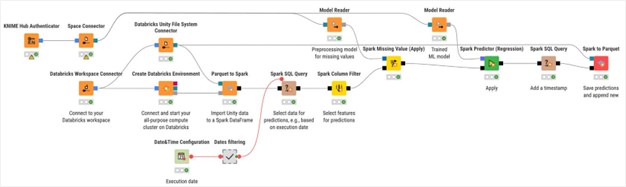
Come preparare un flusso di lavoro per la pianificazione.

Come preparare un flusso di lavoro per le richieste API REST.
Considerazioni finali
L’integrazione di Databricks e KNIME fornisce ai data engineer e ai professionisti del machine learning un potente toolkit complementare.
L’ambiente intuitivo e low-code di KNIME accelera la progettazione e la sperimentazione delle pipeline, mentre l’infrastruttura scalabile di Databricks consente l’elaborazione efficiente di grandi set di dati e l’addestramento di modelli ad alte prestazioni.
Esplorando i workflow di esempio, prototipando localmente e trasferendo i carichi di lavoro su Databricks, i vari team possono collaborare per sviluppare soluzioni ML riproducibili e pronte per la produzione, più facili da gestire, monitorare e migliorare.
Questo conclude la nostra esplorazione di Databricks e KNIME per il machine learning.
Pronti per iniziare a sperimentare?
Esplorate il corso ufficiale KNIME Databricks per l’IA, scaricate KNIME Analytics Platform e collegatevi al vostro spazio di lavoro Databricks oggi stesso.




