The easiest form of data to load into a SQL database is fully structured. Comma separated values (CSV) files can be loaded into a tabular structure without any further transformations. However, data is not always delivered in such a format. In this blog I want to look at semi-structured data and how to structure it in Snowflake.
What is semi-structured data
In the formal definition, semi-structured data is data that does not follow tabular structure, but does contain tags and metadata to separate semantic elements and establish hierarchies of records and fields. Common examples of semi-structured data are JSON and XML files, which are both used to transfer data.
Below is an example of a fictional item order in the JSON format. It contains an identification number and the details for the order.
{
"type": "itemOrder",
"id": "124",
"customer": {
"id": "7",
"name": "John Doe",
"address": "101 Main street"
},
"store": {
"id": "5",
"address": "63 Broad Way"
},
"item": {
"id": "35",
"price": "72.00"
}
}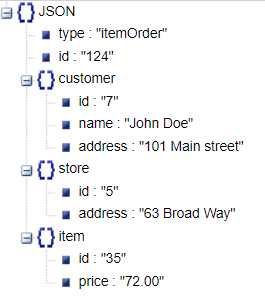
While this block clearly contains all the relevant data, I can not load it directly into a tabular structure. The data is missing a database schema, and several keys occur multiple times in the hierarchy. If I were to ask for the value address in this data I’d end up with two different answers, and for id I’d even get four.
Structuring the data
So how do we structure this semi-structured data in Snowflake? The first step for a large json dataset to load the entire file into a variant type column, which can hold semi-structured and unstructured data. We can then use this column to execute structuring functions. In case of a small piece of json, we can use the results of the parse_json function to directly interpret a json string.
Snowflake allows us to instantly flatten semi-structured data using the flatten function. With this function we can transform the JSON above into the following table:
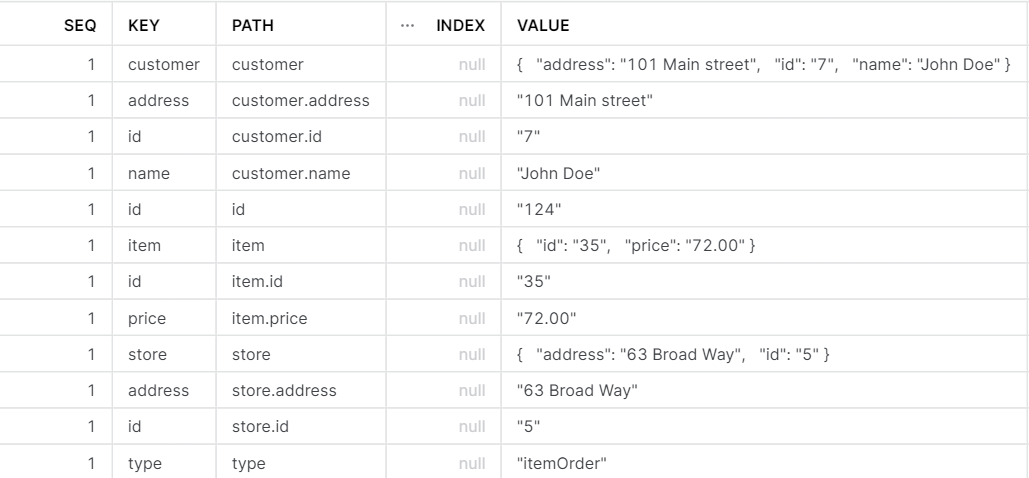
Because Snowflake also resolved the path to each key, it is easy to distinguish the duplicate keynames from each other. Following the rules of data normalization, we would probably want to create different tables for customer, item and store details.
When dealing with a JSON block in a variant column, Snowflake allows us to directly retrieve values when we provide the full path to the key using colon (:) notation. Since we still need to specify a datatypes, we can use the double colon (::) to cast these on all the values. For example, the following code will retrieve the customer data for proper structured storage:
column:customer:id::int as customer_id,
column:customer:address::varchar as customer_address,
column:customer:name::varchar as customer_nameWe have now succesfully structured our semi-structured data in Snowflake, making it easy to aggregate and analyze.



