
Del BI a la GenAI: comienza el viaje
Este blog marca el punto de partida de nuestra serie, dividida en cuatro partes, que explica cómo KNIME y Databricks se integran en el ciclo de vida de los datos y la IA. Comenzamos con la inteligencia empresarial (BI): mostramos cómo KNIME se conecta de forma sencilla e intuitiva a Databricks, lo que permite a los analistas consultar fuentes de datos gestionadas, explorar Unity Catalog y procesar todo de forma segura dentro de Databricks.
Los próximos blogs de esta serie profundizarán en estos temas:
- Ingeniería de datos. Cómo la escalabilidad de Databricks y los flujos de trabajo de KNIME aceleran la preparación y la transformación de los datos.
- Aprendizaje automático. Cómo se pueden entrenar y utilizar los modelos alojados en Databricks a través de KNIME.
- IA generativa. Cómo los LLM, las canalizaciones RAG y los agentes amplían el análisis hacia nuevas fronteras.
Por qué combinar KNIME y Databricks
KNIME es una plataforma de código abierto que permite a los usuarios diseñar flujos de trabajo de forma visual. Con KNIME es posible incorporar componentes de inteligencia artificial, aprendizaje automático y análisis avanzado en un flujo de trabajo, manteniendo una interfaz intuitiva para los usuarios menos técnicos.
Databricks, por su parte, es una plataforma en la nube escalable para el procesamiento y análisis de datos, que ofrece herramientas para la gestión segura de conjuntos de datos, Delta Lake y Unity Catalog.
La combinación de KNIME y Databricks permite a las organizaciones:
- Reducir la necesidad de escribir código para los analistas y los equipos de BI. De hecho, los flujos de trabajo de arrastrar y soltar de KNIME permiten a los analistas crear sofisticadas canalizaciones de datos sin escribir código Spark o SQL complejo. Esto permite a los equipos de BI trabajar de forma más independiente y a los ingenieros de datos centrarse en tareas de mayor valor.
- Acceder y procesar conjuntos de datos a gran escala en la nube. Databricks proporciona un entorno de procesamiento y almacenamiento altamente escalable, lo que permite a los usuarios de KNIME trabajar directamente con conjuntos de datos de gran tamaño. En lugar de mover los datos entre sistemas, es posible consultar y procesar los datos «in situ», aprovechando los clústeres de Databricks para obtener rendimiento y eficiencia.
- Combinar múltiples fuentes de datos de forma segura. Muchas empresas dependen de ecosistemas de datos diversificados, desde almacenes de datos en la nube y bases de datos locales hasta aplicaciones SaaS. Los conectores de KNIME y la gobernanza segura de datos de Databricks (incluido Unity Catalog) permiten integrar diferentes fuentes, al tiempo que garantizan el cumplimiento normativo y el control de acceso.
- Automatizar los procesos de análisis de extremo a extremo. Con KNIME orquestando los flujos de trabajo y Databricks proporcionando una potencia de procesamiento escalable, las organizaciones pueden automatizar toda la cadena de datos. Desde la adquisición hasta la preparación, el aprendizaje automático y ahora la GenAI, es posible crear procesos automatizados que reducen el trabajo manual, mejoran la reproducibilidad y aceleran los tiempos de análisis.
Ventajas clave de la integración
1. Entorno sin código
La interfaz visual de los flujos de trabajo de KNIME reduce drásticamente la necesidad de escribir código SQL o PySpark. Los analistas pueden arrastrar y configurar nodos KNIME para realizar tareas como:
- Cargar datos desde Databricks
- Limpiar y transformar datos
- Realizar cálculos y agregaciones
- Generar informes interactivos
2. Colaboración mejorada
Los flujos de trabajo de KNIME son reutilizables y compartibles, lo que permite la colaboración entre equipos. Los analistas de datos, los ingenieros de datos y los usuarios empresariales pueden trabajar con los mismos conjuntos de datos sin cambiar de entorno ni escribir código.
3. Acceso directo a datos y modelos GenAI
La integración permite un acceso sencillo a:
- Databricks SQL Warehouse
- Sistemas de archivos y tablas Delta
- Modelos de IA generativa preentrenados o personalizados
- API REST
Todo ello ayuda a reducir la exportación y la duplicación de datos y permite realizar análisis y generar informes en tiempo real.
4. Integración y gobernanza de datos
Combina los datos de Databricks con fuentes externas como CSV, Excel o sistemas de almacenamiento en la nube. La gobernanza y el cumplimiento se garantizan mediante el uso de Unity Catalog y la gestión de credenciales de KNIME Hub.
5. Eficiencia de costes y escalabilidad
El preprocesamiento puede realizarse de forma local, en KNIME Hub o directamente en Databricks, ya que los clústeres Databricks con escalabilidad automática garantizan un alto rendimiento. Todo ello optimiza tanto los costes de cálculo como los tiempos de procesamiento.
6. Implementación más rápida
Una vez diseñado un flujo de trabajo, se puede distribuir al instante, lo que permite a los equipos de BI proporcionar paneles de control y aplicaciones de datos mucho más rápidamente que con las soluciones tradicionales basadas en código.
Conexión y autenticación
- Conecta KNIME a Databricks a través de Databricks Workspace Connector.
- Gestiona las credenciales en KNIME Hub: admite OAuth2 U2M, M2M y tokens de acceso personales.
- Accede a todos los recursos de Databricks utilizando nodos KNIME dedicados: SQL Warehouse, sistemas de archivos, modelos GenAI y API REST.
Esta configuración garantiza una integración segura y sin interrupciones, minimizando la complejidad de la configuración.
El conector Databricks Workspace es el nodo clave para integrar Databricks en un flujo de trabajo KNIME. Siga los pasos que se indican a continuación para configurarlo.
1 – Proporciona la URL del espacio de trabajo de Databricks:
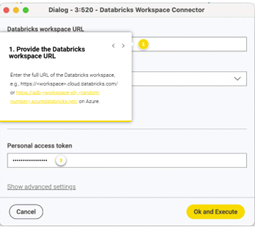
2 – Selecciona el tipo de autenticación:
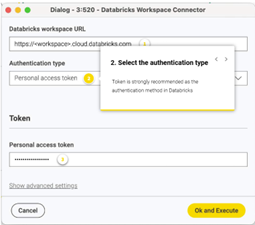
3 – Proporciona el token de acceso personal:

Procesamiento de datos con KNIME y Databricks
KNIME simplifica la creación de flujos de trabajo integrales que combinan la flexibilidad local con toda la potencia de Databricks. Dependiendo del caso de uso, se puede trabajar con Unity Volumes, ejecutar consultas en tablas de Databricks en SQL Warehouse o ejecutar trabajos Spark en clústeres de Databricks.
1. Unity Volumes
Una vez conectado al espacio de trabajo de Databricks, se puede acceder a Unity Volumes directamente desde KNIME. Gracias a los nodos de gestión de archivos de KNIME, los archivos almacenados en Unity Volumes se comportan exactamente igual que los archivos de cualquier otro sistema. Es posible cargarlos, descargarlos, moverlos u organizarlos directamente desde su flujo de trabajo.
- Los conjuntos de datos pequeños se pueden importar directamente a las tablas de KNIME.
- Los conjuntos de datos de gran tamaño pueden permanecer en Databricks, donde es posible consultarlos con SQL o procesarlos con los nodos Spark, evitando así transferencias que requieren mucho tiempo.
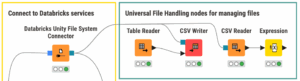
Esta configuración permite a los equipos gestionar sus archivos de forma centralizada en Databricks y, al mismo tiempo, trabajar con ellos visualmente con KNIME.
2. Consultar el almacén SQL local sin código
Para los datos estructurados, Databricks SQL Warehouse se integra perfectamente con la extensión KNIME Database. En lugar de escribir SQL, basta con arrastrar y configurar los nodos dedicados:

- Utiliza el nodo DB Table Selector para elegir la tabla que deseas leer.
- Aplica los nodos Database de KNIME, como el nodo DB Groupby, para transformar los datos.
- O escribe una consulta personalizada con el nodo DB Query.
Entre bastidores, KNIME genera automáticamente código SQL que se ejecuta directamente en Databricks, manteniendo los datos donde están y aprovechando la potencia de cálculo de Databricks. Si es necesario, los resultados se pueden llevar a KNIME con el nodo DB Reader.
Esto resulta especialmente útil para los profesionales de BI que desean explorar y analizar visualmente las tablas de Databricks, sin utilizar código y trabajando a gran escala.
3. Simplificar el acceso a Databricks con componentes compartidos
Para los usuarios menos experimentados, los ingenieros de datos pueden encapsular una canalización que incluya la conexión a Databricks, la autenticación e incluso las etapas iniciales de la consulta en componentes KNIME. Una vez compartidos, estos componentes pueden utilizarse dentro de los flujos de trabajo como cualquier otro nodo, con la ventaja de ocultar la complejidad de la canalización y garantizar al mismo tiempo la fiabilidad y la gobernanza. Los analistas de negocios o los expertos en BI pueden utilizar estos componentes para acceder a datos limpios y fiables sin preocuparse por las credenciales o la infraestructura.
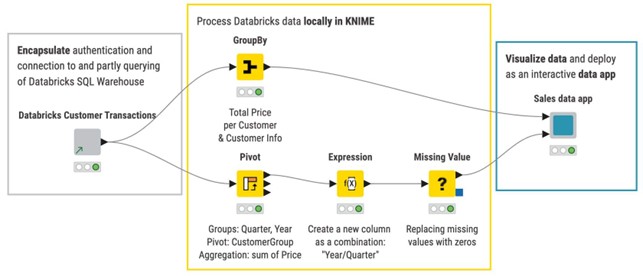
4. Un único flujo de trabajo
Lo que hace que la integración KNIME-Databricks sea tan potente es que todo esto se puede combinar en un único flujo de trabajo, donde es posible:
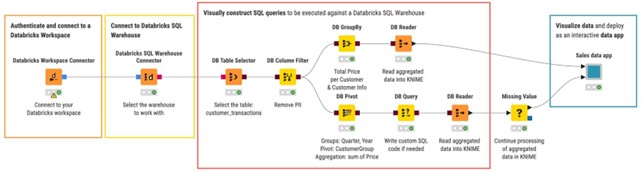
- Gestionar y organizar archivos en Unity Volumes.
- Realizar consultas en tablas estructuradas en SQL Warehouse.
- Almacenar los resultados en varios formatos: paneles, informes PDF o aplicaciones de datos interactivas.
El resultado final es un entorno totalmente controlado y con poco código en el que los datos pueden permanecer en Databricks, pero la información se puede proporcionar de forma rápida y visual a través de KNIME.
Consideraciones finales
La unión de Databricks y KNIME para la inteligencia empresarial permite a los equipos crear informes, paneles de control y aplicaciones de datos sin escribir una sola línea de código. Al combinar las capacidades de flujo de trabajo visual de KNIME con el análisis a escala de nube de Databricks, las organizaciones pueden:
- Acelerar la obtención de información. Los analistas pueden conectarse rápidamente a las tablas de Databricks, explorar conjuntos de datos controlados a través de Unity Catalog y diseñar flujos de trabajo de BI en el entorno visual de KNIME. Esto reduce el tiempo dedicado a escribir consultas y preparar datos manualmente, lo que permite a los equipos proporcionar información a las partes interesadas con mayor rapidez.
- Mejorar la colaboración. Los flujos de trabajo de KNIME están diseñados para ser transparentes y compartibles, lo que facilita que los usuarios técnicos y no técnicos colaboren en los mismos procesos de BI. En combinación con la plataforma de datos centralizada de Databricks, esto crea una única fuente de verdad que mejora la alineación entre departamentos.
- Garantizar la gobernanza y la seguridad. Databricks proporciona gobernanza de datos, seguridad y control de acceso a nivel empresarial, mientras que KNIME garantiza que los flujos de trabajo cumplan estas políticas. Juntos, permiten a las organizaciones explorar y generar informes incluso con datos sensibles en plena conformidad, reduciendo los riesgos y manteniendo la flexibilidad.
- Reducir costes y acelerar la implementación. Al mantener todo el procesamiento de datos en Databricks y eliminar la necesidad de mover o duplicar datos, las organizaciones ahorran en costes de infraestructura y almacenamiento. El entorno sin código de KNIME acelera la implementación de flujos de trabajo y paneles de BI, lo que reduce el tiempo necesario para convertir una idea en un flujo de trabajo en producción.
Ya sea para gestionar conjuntos de datos de gran tamaño, crear aplicaciones GenAI o proporcionar información útil a las partes interesadas, esta integración hace que los flujos de trabajo de BI sean más accesibles y potentes.
Optimiza tu trabajo y tu tiempo, contacta con nosotros para empezar a hacerlo.



