
El aprendizaje automático (ML) ha tenido que lidiar durante mucho tiempo con el compromiso entre escalabilidad y usabilidad. Juntos, Databricks y KNIME eliminan esta barrera: al combinar la infraestructura en la nube a gran escala de Databricks con los flujos de trabajo visuales y de bajo código de KNIME, los equipos pueden simplificar la preparación de datos, acelerar el entrenamiento de modelos y facilitar la implementación. El resultado es una potente sinergia que permite a los profesionales del ML y a los ingenieros de datos reducir la complejidad para los usuarios menos técnicos y desarrollar soluciones listas para pasar a producción más rápidamente.
Este tercer artículo de nuestra serie Databricks & KNIME profundiza en cómo las dos plataformas se integran para crear flujos de trabajo de aprendizaje automático escalables, desde la preparación de datos y la ingeniería de características hasta el entrenamiento y la implementación de modelos, lo que permite tanto a los equipos técnicos como a los usuarios empresariales crear soluciones robustas y listas para la producción.
De la BI a la GenAI: el camino recorrido hasta ahora
En una serie de cuatro blogs, estamos examinando las formas en que KNIME y Databricks se integran para dar soporte a cada fase del ciclo de vida de los datos y la IA. En los blogs anteriores hemos tratado los aspectos fundamentales de:
- Business Intelligence. Cómo KNIME se conecta a Databricks a través de conectores seguros y fáciles de usar, lo que permite a los analistas consultar las tablas de Databricks, explorar Unity Catalog y mantener todo el procesamiento de datos dentro de Databricks.
- Ingeniería de datos. Cómo la escalabilidad de Databricks y los flujos de trabajo de bajo código de KNIME pueden simplificar la preparación, la combinación y la transformación de datos a gran escala, eliminando los silos tradicionales y optimizando los procesos.
Ahora, en esta tercera fase, partimos de los fundamentos de la BI y la ingeniería de datos para mostrar cómo Databricks y KNIME pueden colaborar para crear soluciones en el ámbito del aprendizaje automático.
Escalar los flujos de trabajo de aprendizaje automático con Databricks y KNIME
Aprovechando la potencia de cálculo de Databricks junto con la intuitiva plataforma de KNIME, las organizaciones pueden beneficiarse de análisis avanzados y aprendizaje automático, simplificando procesos complejos y acelerando al mismo tiempo la obtención de información útil. Le guiaremos a lo largo de un recorrido en el que aprenderá a:
- Conectar Databricks a los flujos de trabajo de KNIME, creando un canal para el procesamiento y el análisis de datos.
- Procesar y analizar conjuntos de datos a gran escala y entrenar modelos de aprendizaje automático de manera eficiente utilizando los nodos Spark visuales de KNIME en los clústeres de Databricks.
- Automatizar flujos de trabajo o transformarlos en soluciones implementables, como aplicaciones de datos interactivas o API REST.
Siguiendo este enfoque, adquirirá la capacidad de crear flujos de trabajo de ML escalables y listos para la producción que aprovechan al máximo las capacidades tanto de KNIME como de Databrick, sin necesidad de escribir código Spark.
Creación de flujos de trabajo de ML en KNIME con Databricks
Un proyecto típico de ML pasa de la adquisición de datos a la distribución:
- Importa conjuntos de datos de Databricks a KNIME mediante el conector Databricks Workspace Connector.
- Limpia y transforma los datos utilizando los nodos visuales y habilitados para Spark de KNIME.
- Entrena el modelo de forma escalable en el entorno Databricks y vuelve a importar el modelo resultante a KNIME para su validación, pruebas de IA explicable y puesta a punto final.
- Guarda el modelo validado.
Este ciclo es iterativo, por lo que los cambios en las características, el reentrenamiento y la supervisión mantienen la solidez y la reproducibilidad del proceso en los entornos de desarrollo y producción.
Ahora exploraremos este proceso en detalle, utilizando un flujo de trabajo de KNIME de la guía práctica. Este flujo de trabajo forma parte de los cursos gratuitos «Getting Started» disponibles en el KNIME Community Hub: aquí puede encontrar todo el material.
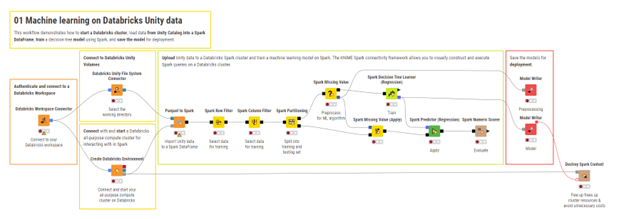
1. Preparación de datos e ingeniería de características. Pasos fundamentales para procesar datos de Databricks con Spark en KNIME
Como se describe en el blog Data Engineering, KNIME permite limpiar, unir y transformar grandes conjuntos de datos a gran escala con Spark. Para el aprendizaje automático, la misma metodología se puede extender a la ingeniería de características. De hecho, los nodos Spark de KNIME permiten conectarse a un clúster Databricks, crear un contexto Spark y procesar directamente los datos de Unity Catalog sin tener que escribir código Spark. El flujo de trabajo suele seguir estos pasos:
- Crea un contexto Spark con el nodo Create Databricks Environment.
- Importa tablas o archivos de Unity Catalog para utilizarlos como Spark DataFrames.
- Transforma y modela las características del modelo utilizando los nodos habilitados para Spark o las canalizaciones Spark ML.
- Exporta los datos o características transformados de nuevo a Databricks.
- Destruye el contexto Spark para liberar recursos.
Esto garantiza un preprocesamiento escalable para las tareas de ML, manteniendo los datos seguros en Databricks.
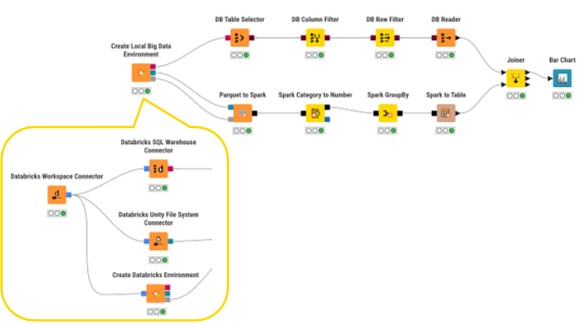
2. Prototipado de flujos de trabajo Spark en local
Como se ha presentado en el blog Data Engineering, el nodo Create Local Big Data Environment de KNIME permite crear prototipos de flujos de trabajo Spark sin utilizar un clúster Databricks en vivo. Esto resulta especialmente útil para las pruebas y la validación, ya que se pueden utilizar muestras de datos representativas a nivel local. A continuación, una vez validadas la lógica y las transformaciones, se puede escalar el mismo flujo de trabajo sustituyendo los conectores Databricks, lo que minimiza los costes de desarrollo y garantiza la preparación para la producción.
3. Entrenamiento y evaluación de modelos. Entrenamiento a gran escala con Spark.
KNIME implementa el ciclo de aprendizaje automático como paradigma Learner – Predictor:
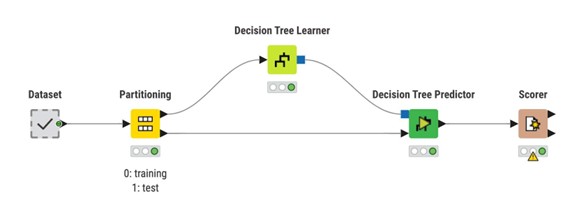
- Un nodo Learner adapta un modelo a los datos de entrenamiento.
- Un nodo Predictor aplica ese modelo a datos no vistos.
- Un nodo Scorer u otros nodos de evaluación miden el rendimiento del modelo.
Esta separación mantiene los flujos de trabajo modulares y simplifica el intercambio de algoritmos o fases de preprocesamiento.
Cuando el conjunto de entrenamiento crece más allá de la capacidad de una sola máquina, también es posible utilizar el mismo modelo Learner – Predictor en Spark y aprovechar la potencia de cálculo de Databricks. El flujo de trabajo es sencillo:

- Crea un contexto Spark conectado al clúster Databricks.
- Carga los datos en un Spark DataFrame (desde Unity Catalog, Parquet/CSV, etc.).
- Divide los datos (entrenamiento/prueba o entrenamiento/validación/prueba) utilizando el nodo Spark Partitioning para que las divisiones se realicen en el clúster.
- Aplica los nodos Spark Learner (por ejemplo, algoritmos Spark MLlib o bibliotecas integradas como H2O) para entrenar los modelos con los datos distribuidos.
- Utiliza los nodos Spark Predictor para realizar predicciones con los datos de prueba y mide el rendimiento del modelo con los nodos Scorer/metrics (todos los cálculos se realizan en el clúster y los datos permanecen en Databricks).
- Guarda los resultados (modelos, métricas, tablas transformadas) en el formato deseado (Unity Catalog, Parquet, tablas KNIME).
Esto permite realizar los cálculos más pesados de forma remota, reducir los tiempos de entrenamiento y preservar la reproducibilidad.
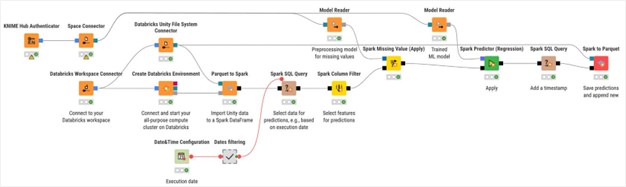
4. Implementación del modelo
El entrenamiento es solo la mitad del trabajo, la producción requiere el empaquetado y la distribución del modelo. En KNIME, por lo general, la lógica es la siguiente:
- Guarda el modelo y los artefactos de preprocesamiento con los nodos Model Writer para que se pueda reproducir toda la canalización de evaluación.
- Ensambla un flujo de trabajo de predicción que cargue los modelos, aplique el mismo preprocesamiento y devuelva las predicciones.
- Pon en producción el flujo de trabajo:
- Carga y versiona el flujo de trabajo en KNIME Community Hub/KNIME Business Hub.
Selecciona un modo de distribución: planifica el flujo de trabajo para predicciones por lotes regulares, publícalo como una aplicación de datos interactiva para los usuarios empresariales o exponlo como una API REST para que los servicios externos puedan solicitar predicciones.

Consideraciones finales
La integración de Databricks y KNIME proporciona a los ingenieros de datos y a los profesionales del aprendizaje automático un potente conjunto de herramientas complementarias. El entorno intuitivo y de bajo código de KNIME acelera el diseño y la experimentación de los flujos de trabajo, mientras que la infraestructura escalable de Databricks permite el procesamiento eficiente de grandes conjuntos de datos y el entrenamiento de modelos de alto rendimiento.
Al explorar los flujos de trabajo de ejemplo, crear prototipos localmente y transferir las cargas de trabajo a Databricks, los distintos equipos pueden colaborar para desarrollar soluciones de aprendizaje automático reproducibles y listas para la producción, más fáciles de gestionar, supervisar y mejorar.
Con esto concluye nuestra exploración de Databricks y KNIME para el aprendizaje automático.
¿Listo para empezar a experimentar? Explora el curso oficial KNIME Databricks for AI, descarga KNIME Analytics Platform y conéctate a tu espacio de trabajo Databricks hoy mismo.
¿Quieres profundizar más? Contacta con nosotros para un asesoramiento gratuito.



