In this blog, we are going to discuss how Snowflake allows to easily interpret semi-structured data through its Schema Detection feature.
This feature helps gaining time when setting up the tables that should contain the data to import; thus, it also decrease the amount of effort at the beginning of data ingestion.
N.B. on Supported Formats: This feature is currently unavailable for all file formats. It is limited to Apache Parquet, Apache Avro, and ORC files.
What is Snowflake INFER SCHEMA?
Let’s picture one of these scenarios: we are dealing with a semi-structured file composed of a huge number of fields. Or we have to bulk-load a big amount of semi-structured files – each with its own set of fields – in a staging area.
In both cases we would have to prepare the table(s) ready to ingest the data from the files, paying attention to define the names and the data types correctly.
The idea, in principle, would be to automate this data pipeline; but, having to interpret the file structure every time, crashes with it.
Theoretically, Snowflake has a native support for semi-structured data, either through copying the whole data into a variant column or by querying the data directly from the staged files using external tables. However, at some point, a structure of the datasets that are included in the files must eventually be provided manually.
As a solution, Snowflake is able to automatically detect the structure of file and to infer the schema a table.
Particularly, the function INFER_SCHEMA helps detecting and returns the schema from a staged file. This SQL statement supports external stages and internal (user or named) stages. Simply as it sounds, it does not support table stages as we are indeed trying to form one starting from the file.
Moreover, it is fundamental to provide a file format to interpet the file correctly.
How to use INFER SCHEMA?
Here an example of how it works.
Let’s infer the schema of a table from a AVRO file. To work, it needs a stage and a file format:
CREATE FILE FORMAT my_avro_format
TYPE = AVRO;
//Creation of a stage, remember to populate it with a AVRO file to use as a template!
CREATE STAGE AVRO_Stage
FILE_FORMAT = my_avro_format;
Now, we can actively use the command:
SELECT *
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@AVRO_Stage'
, FILE_FORMAT=>'my_avro_format'
)
);
The result of this query should be of this kind:
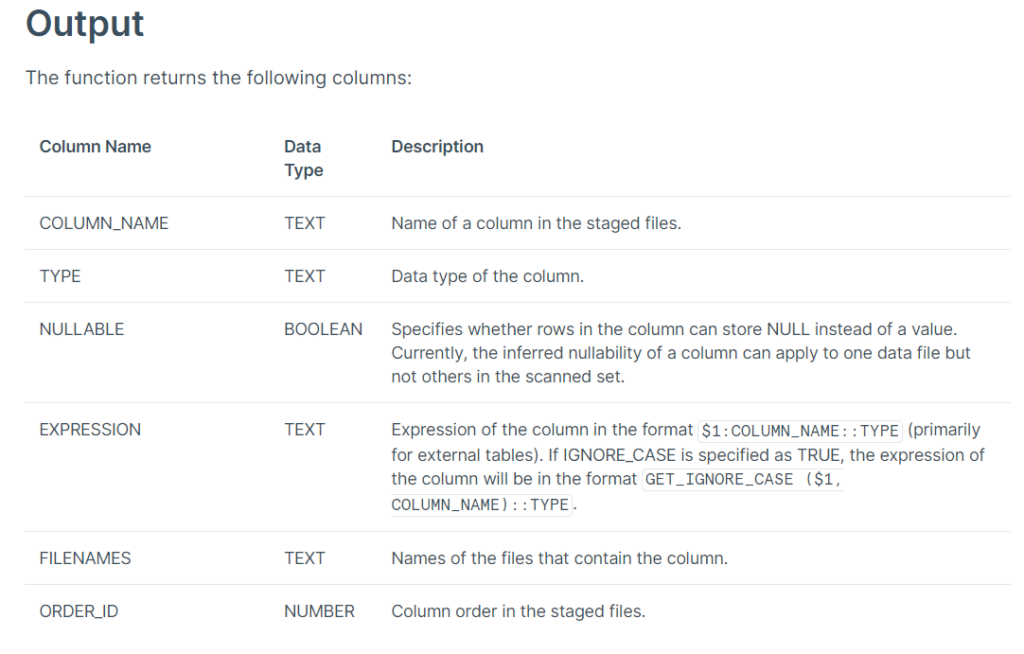
It works! Thus, we can create a table from this schema. It means we won’t have to specify each column name and variable type:
CREATE OR REPLACE TABLE AVRO_Upload
USING TEMPLATE ( SELECT ARRAY_AGG(OBJECT_CONSTRUCT(*))
FROM TABLE(
INFER_SCHEMA(
LOCATION=>'@AVRO_Stage'
, FILE_FORMAT=>'my_avro_format'
)
)
);
It’s time to fill the table. Match_by_column clause forces to put everything in its own column, despite their name in the AVRO dictionary:
COPY INTO AVRO_Upload
FROM @AVRO_Stage
MATCH_BY_COLUMN_NAME = 'CASE_INSENSITIVE';
//Check the result!
SELECT * FROM AVRO_Upload;
What would happen if we have multiple files with different structures and orders for the same table upload?
Snowflake will list down the union of all file column lists in random order.
Conclusion
We have talked about Schema Detection and the function INFER SCHEMA, explaining what they are and how to set them in place.
We hope you have found this useful!
Have questions about data? Be sure to check our blog.



