When we talk about Business Intelligence we immediately think of the strategies connected to the processes of combining data collection, analysis and archiving to highlight useful information. Typically, this involves collecting data from a company’s IT systems and various external sources. However, this last action can often be problematic if, especially in the case of complex analyses, large storage spaces become necessary to manage the entire dataset.
Snowflake, thanks to one of its tools that makes it unique on the market, guarantees its users to be able to work with large amounts of data owned by third parties without burdening their own storage costs.
Today we talk about Zero-Copy Cloning!
What is Zero-Copy Cloning?
The Zero-Copy Cloning function is a unique option and one of the most powerful features in Snowflake. It allows to create a duplicate of any source table, schema or database by taking a snapshot at any point in time and generating a reference to the units of storage that contain the underlying partitions that define that object.
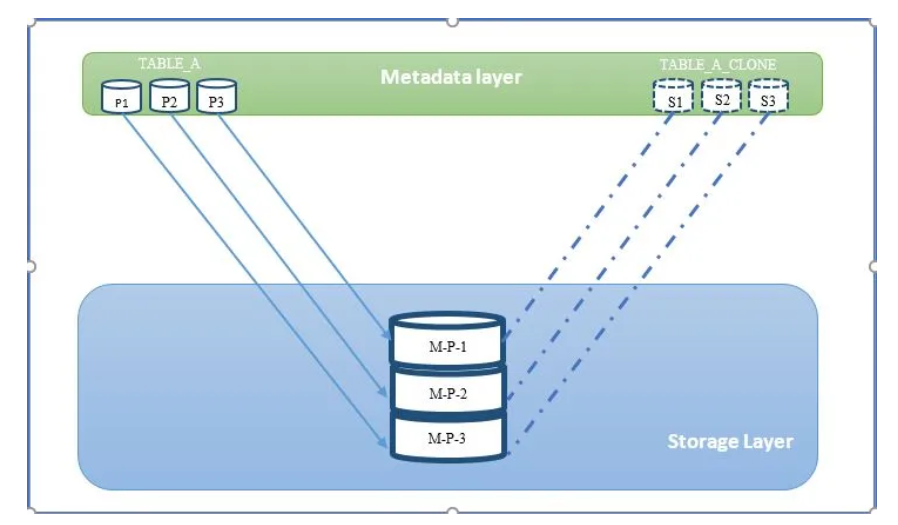
The new clone that appears in the Snowflake instance has no additional storage cost as all the data is shared from the source element. New memory would be necessary only if changing blocks of data relative to the clone. It is then a useful trick either to store data belonging to a third part that is meant to be prompted without being modified or to quickly produce backups without wasting space nor resources.
Moreover, cloning in Snowflake is faster and way much easier than cloning in other databases.
Indeed, a Zero-Copy Clone can be created through this simple query:
SCREATE [OR REPLACE] <object_type> [IF NOT EXISTS] <object_name>
CLONE <source_object_name>;
Which objects can be cloned?
Basically, almost every object (DATABASE | SCHEMA | TABLE | STREAM | STAGE | FILE FORMAT | SEQUENCE | TASK) can be cloned. For databases, schemas and tables, the Zero-Copy Cloning supports an additional AT | BEFORE clause for cloning using Time Travel as well as all DML and DDL procedures.
Snowflake does not allow to clone views, user-defined functions and stored procedures directly. Nevertheless, cloning is recursive: cloning a database or a schema clones all the objects included in there.
What are the advantages?
No data is replicated: instead – as said – Snowflake cleverly produces a reference to the source object, which provides a tremendous benefit on costs for storage and logical execution.
Furthermore, clone generation does not require any special time. Depending on the size of the source item, it could take up to a couple of minutes, but always less than manually recreating the copy of the object.
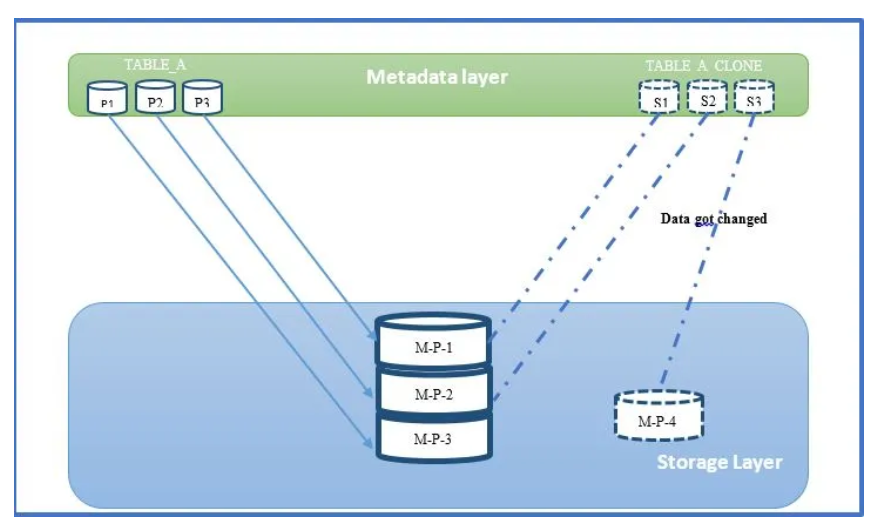
Until any changes gets done, when a user requests information from a cloned object, Snowflake is able to retrieve it from the original storage elements. Despite being entangled, the two objects are two completely different entities; as soon as adjustments to the clone are made, the partition method changes. One could state that this should in theory make storage calculations more complicated… however, since Snowflake manages the compression and archiving, users don’t have to worry about it. The Cloud Services will ensure that the information is always current, feasible and quickly queryable!
In other words, changes to the original object or the clone can be done independently of one another and are preserved by continuous data protection (CDP).
The clone could be reproduced an unlimited amount of times in Snowflake, with each clone having a piece of shared and independent storage. Every object in Snowflake has a unique label that identifies it and, similarly, a «clone group» label that shows whether it is cloned or not. If the two attributes differ, an object is cloned; if they are equal, it is not. This metadata is visible only to the owner and to those roles with special privileges on the object.
What privileges are needed?
To clone an item, a user must have the bare minimum of permissions on it. The current role should have the necessary privileges on the source object (according to its category and properties) in order to generate a clone:
- Databases and Schemas: OWNERSHIP OR NECESSARY PRIVILEGES ON BOTH SOURCE AND CLONE
- Tables: SELECT
- Streams, tasks: OWNERSHIP
- Additional items: USAGE
Why cloning in Snowflake?
There are many reasons to clone an item in any Data Warehouse, not just Snowflake. Most cloning occurs for one of three reasons:
- To support a variety of environments, such as development, testing, and backup.
- To test prospective modifications/development without establishing a new environment and without putting the source object at risk.
- To complete a one-time task that makes use of its own source item.
To wrap up:
To summarize in a few words, Zero-Copy cloning is one of the most useful tools on Snowflake because:
- Saves Time: A user usually has to wait weeks to create a test or development environment from a copy of a data warehouse. Zero-Copy cloning is quick! This technique allows to generate as many copies of the data as needed within minutes.
- Saves Money: Zero-Copy cloning duplicates items without having to reproduce the underlying storage. When a clone is born, it does not utilize any data storage because it maintains all of the parent database existing micro-partitions at the moment of cloning; nonetheless, data can be added, deleted or updated in the clone independently of the original table. Every modification on a clone generates new micro-partitions that relate solely to it and are safeguarded by CDP.
- Easy to use: Cloning is a basic procedure that does not necessitate any special expertise. Zero-Copy cloning is a technology that does not require administrative activities.
Conclusions
In business intelligence departments it is easy to accumulate hundreds of terabytes of redundant storage because generating copies of entire databases for testing or researching. Snowflake allows to remove this storage and to speed up safely the cloning procedure.
Cloning an item duplicates the structure, data and some other aspects of the original table. In cloned elements, the load history of the source is not preserved and data files can be loaded into clones if they were previously loaded into the source object. New metadata are eventually generated as changes may arise; the two elements result in two complete different entities and, thus, clones can be used as a free form of back-up.
This could help a firm save a lot of money. Think about it!
Have questions about data? Be sure to check our blog.



